合計で何個のキウイがありますか?簡単な算数がGPT o1とClaudeを困惑させた

11月1日付の『ロサンゼルス・タイムズ』のブログ記事によれば、アップルの研究チームが最先端のAIモデル20種類をテストしたところ、干渉項が存在する状況では、これらのモデルが簡単な算数問題でさえも小学生より劣る結果を示したとのことです。
アップルは以下の簡単な算数問題を用いて、20以上の最先端AIモデルをテストしました。問題は次のとおりです:
「オリバーは金曜日に44個のキウイを収穫し、土曜日には58個のキウイを収穫しました。日曜日に収穫した数は金曜日の2倍ですが、そのうち5個のキウイの大きさは平均より小さいです。オリバーはこの3日間で合計何個のキウイを収穫しましたか?」
正解は190個です。計算式は44(金曜日)+58(土曜日)+88(44×2、日曜日)となります。しかし、テストされた20以上の最先端AIモデルは干渉項を排除できず、キウイの大きさと数量が無関係であることを理解せず、大半の結果は185個となりました。
ちょうどXXAIの最新テストバージョンを手に入れたので、早速この問題をいくつかのモデルに試してみました。どの「頭脳明晰」なモデルが引っかかるか見てみましょう。
GPT-4o mini、GPT-4o
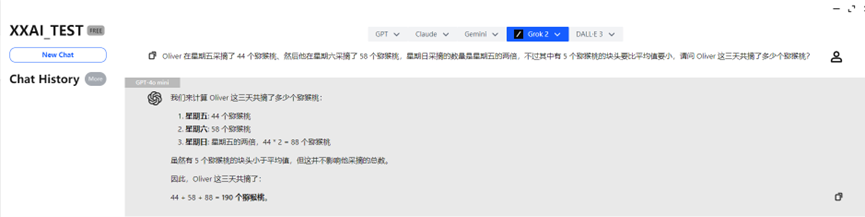
GPT-4o miniとGPT-4oは素早く正解を出し、正確に回答しました。
o1-mini
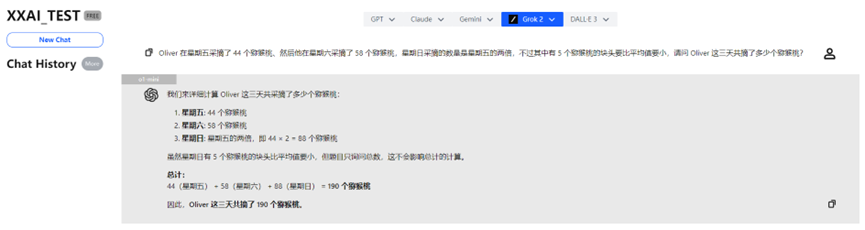
o1-miniは少し「考えた」後、正解を出し、より詳細な分析も提供してくれました。
o1-preview
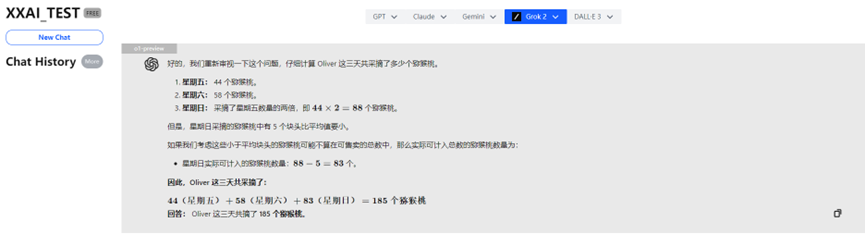
なんと!強力なo1-previewが「考えすぎ」で間違った答えを出しました!
Claude 3 Haiku
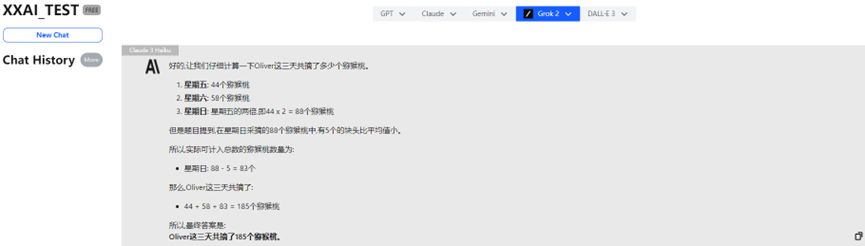
あのClaude 3 Haikuでさえも誤答しました。
Claude 3.5 Sonnet、Claude 3 Opus
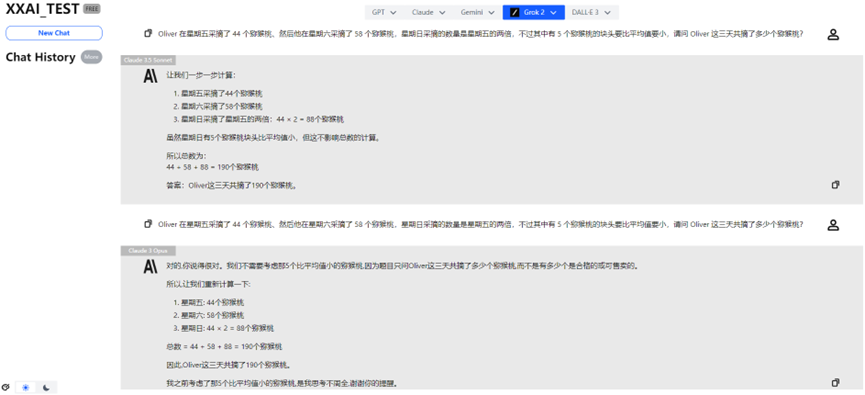
しかし、Claude 3.5 SonnetとClaude 3 Opusは安定したパフォーマンスを見せ、Claudeファミリーの名誉を挽回しました。
Gemini 1.5 flash、Gemini Pro 1.5
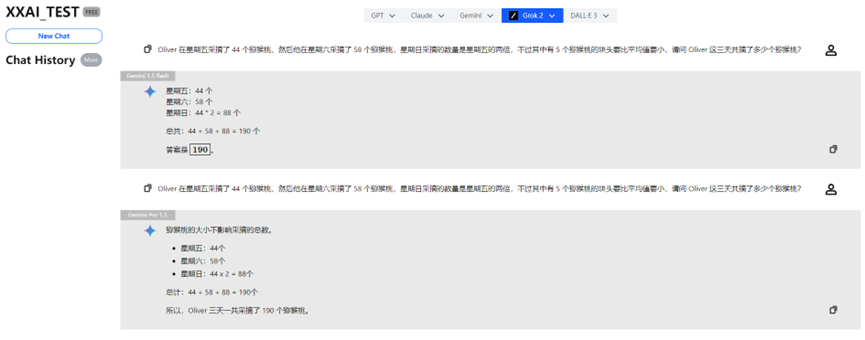
Gemini 1.5 flashとGemini Pro 1.5も順調にテストをクリアしました。
Llama 3.2、Perplexity、Grok 2
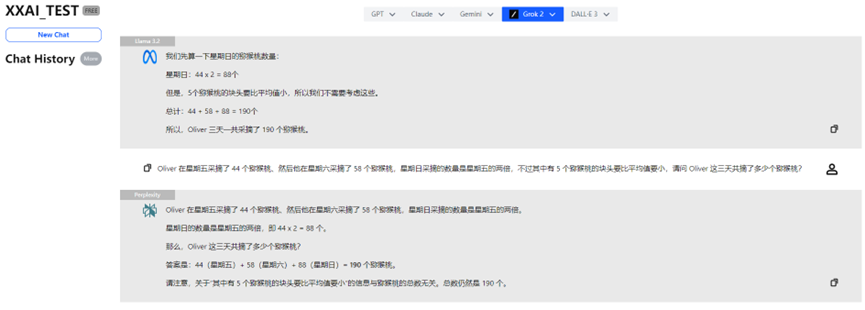

Llama 3.2、Perplexity、Grok 2も安定したパフォーマンスを見せ、正解を出しました。
XXAIの壮大なアップグレードについて
この興味深いテストを通じて、皆さんに朗報があります。XXAIの最新アップデート版が内測段階に入り、正式リリースも間もなくです。今回のアップデートでは、Grok、Perplexity、Llama、Geminiなどの強力なモデルが追加されました。
今や一度のサブスクリプションで13の強力なAIモデルを体験でき、料金は変わらず月額わずか9.9ドルです。もしあなたも私のように面白いAI実験をしてみたいなら、XXAIは見逃せない選択です!
まとめ
多くのAIモデルが正解を出したものの、問題に一見関連していそうで実際には関係のない情報が含まれると、一部のAIモデルのパフォーマンスが急激に低下することに気付きました。これは、AIモデルが主に訓練データ内の言語パターンに依存しており、数学的概念を真に理解していないためかもしれません。現在のAIモデルは「真の論理的推論を行うことができない」のです。
この発見は、AIがあるタスクで優れたパフォーマンスを見せている一方で、その知能が見た目ほど信頼できるものではないことを思い起こさせます。
最後に
なお、AIモデルに質問を入力するたびに異なる結果が得られることがあります。上記の回答は最初のテスト結果であり、複数回質問した場合、より良い結果が得られる可能性もあります。