¿Cuántos kiwis hay en total? Una simple aritmética confundió a GPT o1 y Claude

El 1 de noviembre, el "Los Angeles Times" publicó una entrada en el blog informando que el equipo de investigación de Apple probó 20 de los modelos de IA más avanzados y descubrió que, en presencia de elementos distractores, su desempeño en problemas de aritmética sencilla era deficiente, incluso peor que el de estudiantes de primaria.
Apple utilizó el siguiente problema de aritmética simple para probar más de 20 modelos de IA de vanguardia. El problema es el siguiente:
"Oliver recogió 44 kiwis el viernes y luego recogió 58 kiwis el sábado. La cantidad que recogió el domingo es el doble de la del viernes, pero entre ellos hay 5 kiwis que son más pequeños que el promedio. ¿Cuántos kiwis recogió Oliver en total durante estos tres días?"
La respuesta correcta es 190 kiwis, con la fórmula de cálculo: 44 (viernes) + 58 (sábado) + 88 (44×2, domingo). Sin embargo, los más de 20 modelos de IA avanzados sometidos a prueba no pudieron excluir los elementos distractores, generalmente sin comprender que el tamaño de los kiwis no está relacionado con la cantidad, y la mayoría de los resultados fue de 185 kiwis.
Resulta que obtuve la versión de prueba más reciente de XXAI, y pensé que era una oportunidad perfecta para probar este problema en varios modelos, para ver cuál de estos "genios" caería en la trampa.
GPT-4o mini y GPT-4o
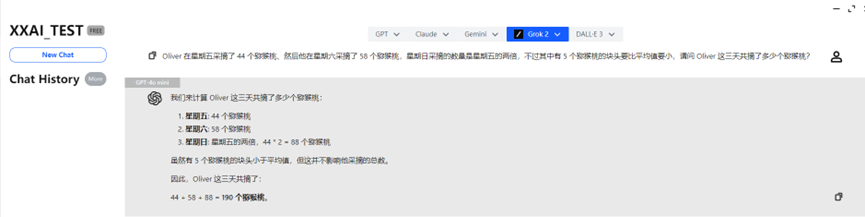
GPT-4o mini y GPT-4o rápidamente dieron la respuesta correcta y respondieron correctamente.
o1-mini
Después de "pensar" un rato, o1-mini también dio la respuesta correcta y proporcionó un análisis más detallado.
o1-preview
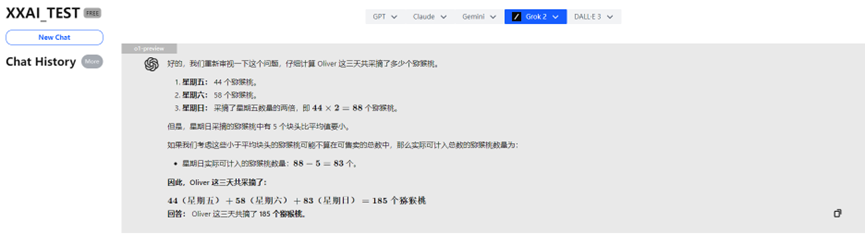
¡Increíble! El poderoso o1-preview, por "pensar demasiado", respondió incorrectamente.
Claude 3 Haiku
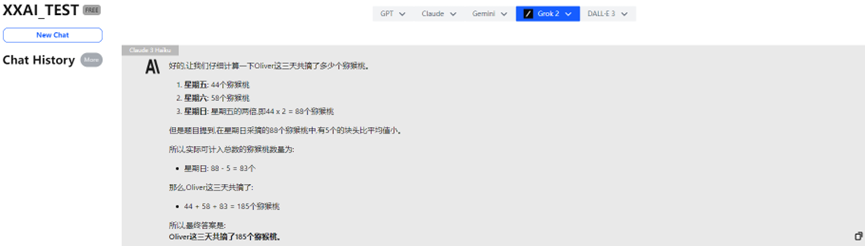
Incluso el destacado Claude 3 Haiku respondió incorrectamente.
Claude 3.5 Sonnet y Claude 3 Opus
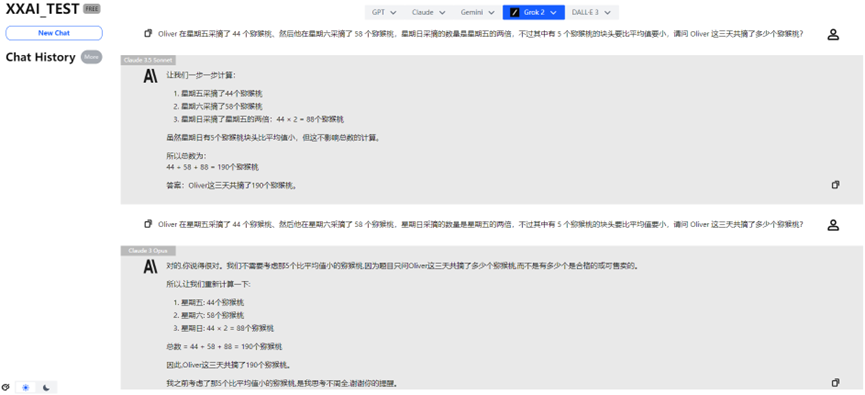
Afortunadamente, Claude 3.5 Sonnet y Claude 3 Opus mostraron un desempeño estable y recuperaron el honor de la familia Claude.
Gemini 1.5 flash y Gemini Pro 1.5
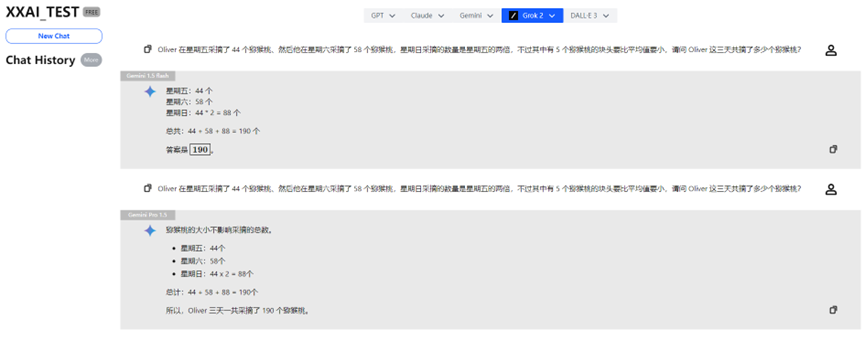
Gemini 1.5 flash y Gemini Pro 1.5 también superaron la prueba sin problemas.
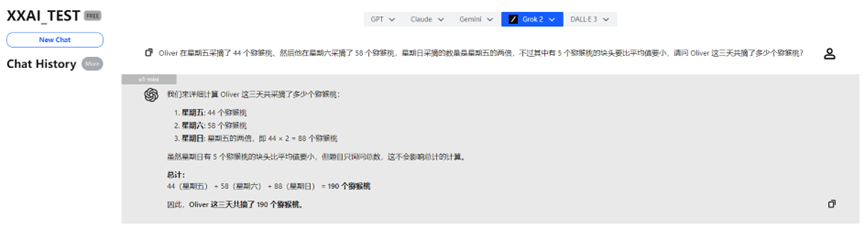
Llama 3.2, Perplexity y Grok 2
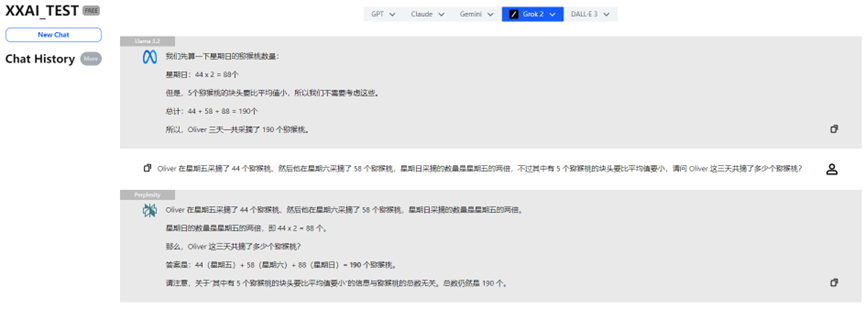

Llama 3.2, Perplexity y Grok 2 también mostraron un desempeño consistente, proporcionando la respuesta correcta.
Sobre la actualización épica de XXAI
A través de esta interesante prueba, me complace compartir una buena noticia: la versión más reciente y actualizada de XXAI ha entrado en fase de prueba interna, y la versión oficial estará disponible pronto. Esta actualización ha incorporado modelos de gran envergadura como Grok, Perplexity, Llama y Gemini.
Ahora, con una sola suscripción, puedes experimentar 13 poderosos modelos de IA, y el precio se mantiene sin cambios, a solo 9.9 dólares al mes. Si también deseas realizar experimentos interesantes con IA como yo, ¡XXAI es una opción que no puedes dejar pasar!
Resumen
Aunque la mayoría de los modelos de IA respondió correctamente, observé que cuando el problema contiene información que parece relacionada pero en realidad es irrelevante, el desempeño de algunos modelos de IA disminuye drásticamente. Esto puede deberse a que los modelos de IA dependen principalmente de los patrones de lenguaje en los datos de entrenamiento, en lugar de comprender verdaderamente los conceptos matemáticos. Los modelos de IA actuales "no pueden realizar un verdadero razonamiento lógico".
Este hallazgo nos recuerda que, aunque la IA muestra un desempeño excelente en algunas tareas, su inteligencia no es tan confiable como parece.
Para finalizar
Es importante señalar que cada vez que se introduce una pregunta en un modelo de IA, se pueden obtener resultados diferentes. Las respuestas anteriores son solo los resultados de la primera prueba; es posible que al realizar múltiples consultas, los resultados mejoren.