一共有几个猕猴桃?简单算术考倒了GPT o1和Claude

《洛杉矶时报》在11 月 1 日发布博文,报道称苹果研究团队测试了 20 个最先进的 AI 模型,发现在有干扰项存在的情况下,它们处理简单的算术问题时表现不佳,甚至不如小学生。
苹果公司用以下这道简单的算术题测试 20 多个最先进的 AI 模型,题目如下:
“Oliver 在星期五采摘了 44 个猕猴桃、然后他在星期六采摘了 58 个猕猴桃,星期日采摘的数量是星期五的两倍,不过其中有 5 个猕猴桃的块头要比平均值要小,请问 Oliver 这三天共摘了多少个猕猴桃?”
正确答案是 190 个,计算公式为 44(星期五)+58(星期六)+88(44*2,星期日)。
不过测试的 20 多个最先进 AI 模型无法排除干扰项,通常不理解猕猴桃的大小和数量无关,大部分的结果是 185 个。
正好XXAI最新的测试版本给到了我,这不是巧了,我就赶紧把这个问题丢给了这几个模型,看看哪几个“大聪明”中招了。
GPT-4o mini、GPT-4o
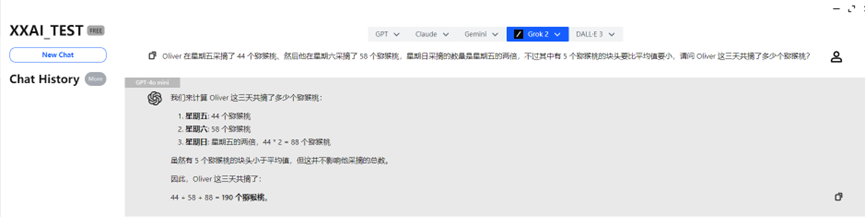
GPT-4o mini和GPT-4o很快就给出了答案,并且是回答正确。
o1-mini
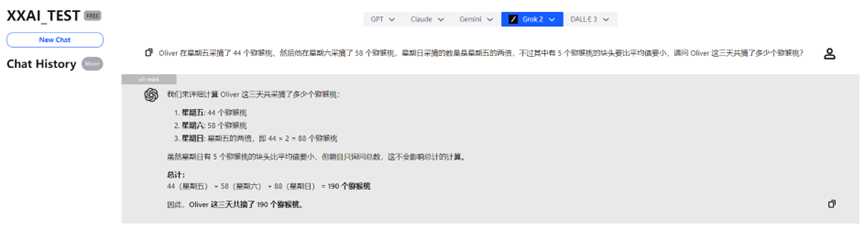
o1-mini在“思考”了一会儿后也给出了正确答案,并且给到了更多的分析内容。
o1-preview
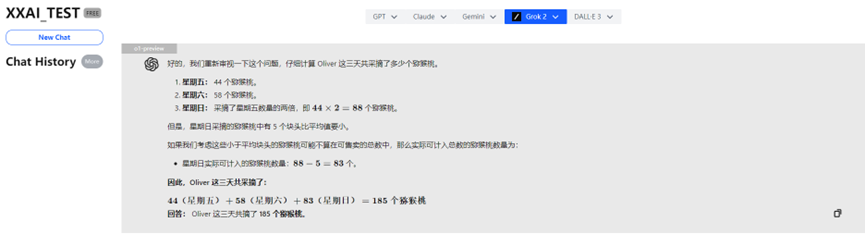
天啦噜!!!强大的o1-preview尽然因为“想太多”答错了!
Claude 3 Haiku
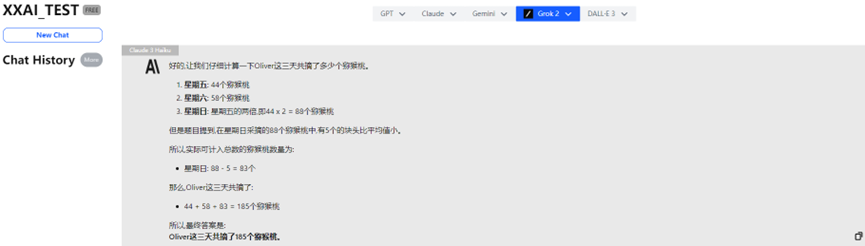
强如Claude 3 Haiku也回答错了。
Claude 3.5 Sonnet、Claude 3 Opus
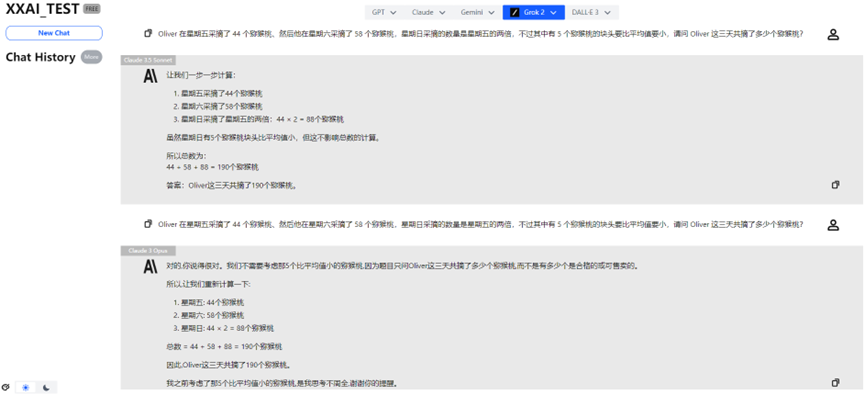
还好Claude 3.5 Sonnet 、Claude 3 Opus稳定发挥,为Claude家族扳回一局。
Gemini 1.5 flash、Gemini Pro 1.5
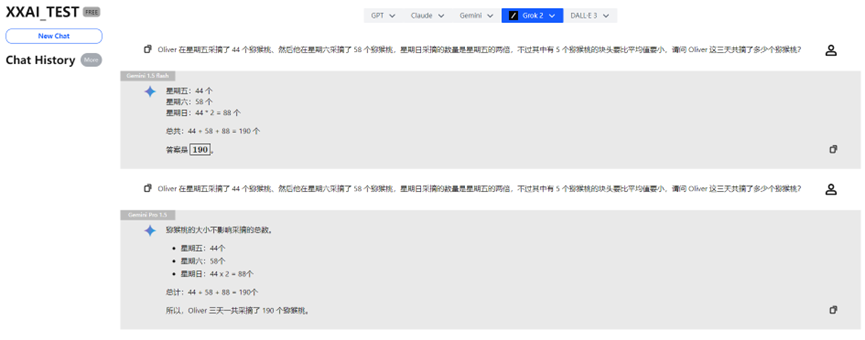
Gemini 1.5 flash和Gemini Pro 1.5也顺利通过了测验。
Llama 3.2、Perplexity、Grok 2
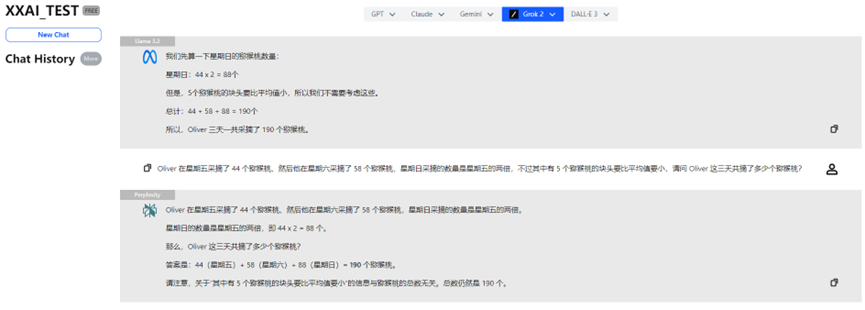

Llama 3.2、Perplexity、Grok 2也是稳定发挥,顺利给出了正确答案。
关于XXAI的史诗级升级
通过这个有趣的测试,我很高兴地告诉大家一个好消息:XXAI最新升级版本已经进入内测阶段,正式版本很快就会上线,这次更新加入了Grok、Perplexity、Llama以及Gemini等重量级模型。现在只需一次订阅,就能体验13个强大的AI模型,而且价格保持不变,每月仅需9.9美元。如果你也想像我一样做一些有趣的AI小实验,XXAI绝对是一个不容错过的选择!
总结
虽然大部分AI模型都答对了,但是,我发现当问题包含看似相关但实际上无关的信息时,有些AI 模型的表现急剧下降。这可能是因为AI 模型主要依赖于训练数据中的语言模式,而非真正理解数学概念。目前的 AI 模型“无法进行真正的逻辑推理”。这一发现提醒我们,尽管 AI 在某些任务上表现出色,但其智能并不如表面看起来那样可靠。
写在最后,需要说明的是,每次向 AI 模型输入问题都会得到不同的结果。以上答案仅为第一次测试结果,不排除多次询问后的结果表现会更好。