Quanti kiwi ci sono in totale? Una semplice operazione aritmetica ha confuso GPT o1 e Claude

Il 1° novembre, il "Los Angeles Times" ha pubblicato un articolo sul blog riferendo che il team di ricerca di Apple ha testato 20 dei modelli di IA più avanzati. Hanno scoperto che, in presenza di elementi distraenti, questi modelli hanno avuto prestazioni scadenti su problemi aritmetici semplici, facendo addirittura peggio degli studenti delle scuole elementari.
Apple ha utilizzato il seguente semplice problema aritmetico per testare oltre 20 modelli di IA all'avanguardia. Il problema è:
"Oliver ha raccolto 44 kiwi venerdì e 58 kiwi sabato. La quantità che ha raccolto domenica è il doppio di quella di venerdì, ma tra questi ci sono 5 kiwi più piccoli della media. Quanti kiwi ha raccolto Oliver in totale in questi tre giorni?"
La risposta corretta è 190 kiwi, con la formula di calcolo: 44 (venerdì) + 58 (sabato) + 88 (44×2, domenica). Tuttavia, i più di 20 modelli di IA avanzati testati non sono riusciti a ignorare gli elementi distraenti, generalmente non comprendendo che la dimensione dei kiwi non è correlata alla quantità. La maggior parte dei risultati era di 185 kiwi.
Casualmente, ho ricevuto l'ultima versione di prova di XXAI. Colta l'opportunità, ho sottoposto questo problema a diversi modelli per vedere quale di questi "geni" sarebbe caduto nella trappola.
GPT-4o mini e GPT-4o
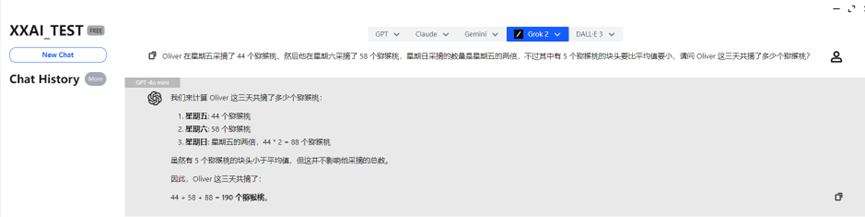
GPT-4o mini e GPT-4o hanno rapidamente fornito la risposta corretta, rispondendo con precisione.
o1-mini
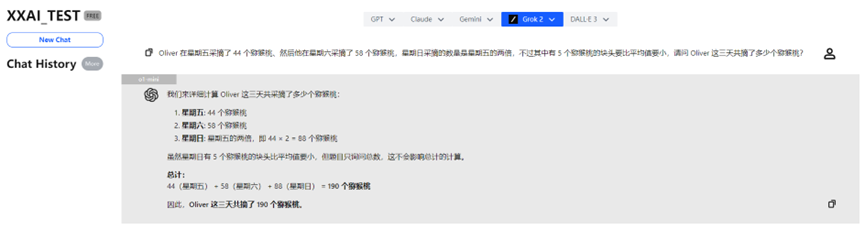
Dopo aver "riflettuto" un attimo, anche o1-mini ha fornito la risposta giusta, accompagnata da un'analisi più dettagliata.
o1-preview
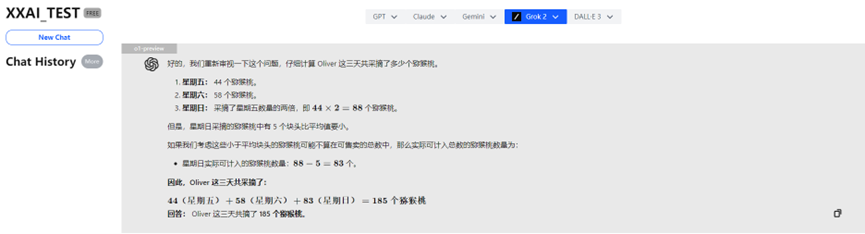
Incredibile! Il potente o1-preview ha sbagliato la risposta a causa di un "eccesso di pensiero"!
Claude 3 Haiku
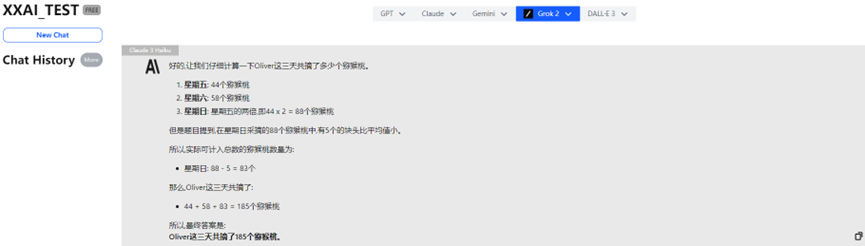
Anche il rinomato Claude 3 Haiku ha dato una risposta errata.
Claude 3.5 Sonnet e Claude 3 Opus
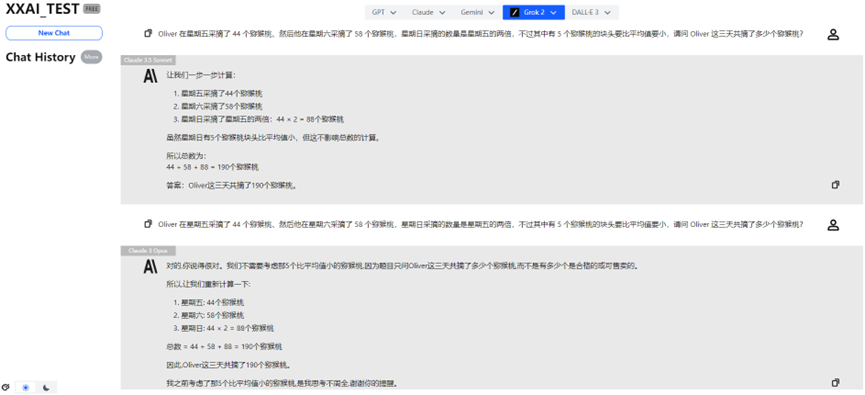
Fortunatamente, Claude 3.5 Sonnet e Claude 3 Opus hanno mostrato prestazioni stabili, ridando orgoglio alla famiglia Claude.
Gemini 1.5 flash e Gemini Pro 1.5
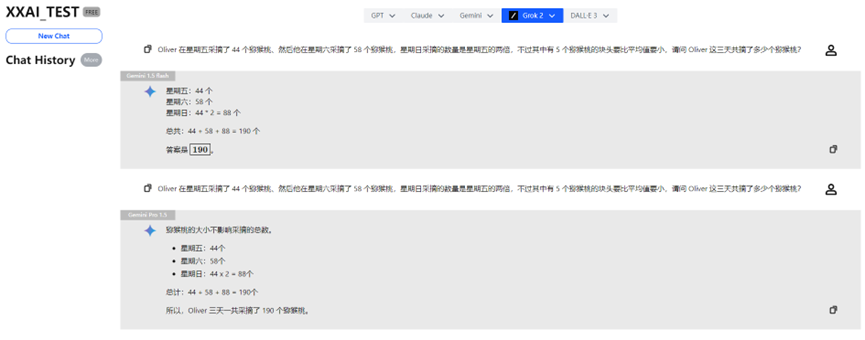
Anche Gemini 1.5 flash e Gemini Pro 1.5 hanno superato il test senza problemi.
Llama 3.2, Perplexity e Grok 2
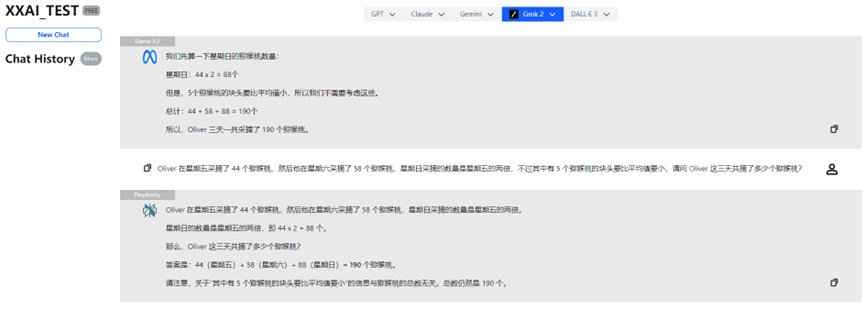

Llama 3.2, Perplexity e Grok 2 hanno anch'essi fornito prestazioni costanti, dando la risposta corretta.
Sull'epico aggiornamento di XXAI
Grazie a questo interessante test, sono felice di condividere una buona notizia con voi: la nuovissima versione aggiornata di XXAI è entrata nella fase di test interno, e la versione ufficiale sarà presto online. Questo aggiornamento ha integrato modelli di rilievo come Grok, Perplexity, Llama e Gemini.
Ora, con un solo abbonamento, potete sperimentare 13 potenti modelli di IA, e il prezzo rimane invariato, a soli 9,9 dollari al mese. Se anche voi volete fare piccoli esperimenti divertenti con l'IA come me, XXAI è un'opzione da non perdere!
Conclusione
Sebbene la maggior parte dei modelli di IA abbia fornito la risposta corretta, ho notato che quando il problema contiene informazioni che sembrano correlate ma in realtà non lo sono, le prestazioni di alcuni modelli di IA diminuiscono drasticamente. Ciò può essere dovuto al fatto che i modelli di IA si basano principalmente sui modelli linguistici presenti nei dati di addestramento, piuttosto che comprendere realmente i concetti matematici. Gli attuali modelli di IA "non sono in grado di eseguire un vero ragionamento logico".
Questa scoperta ci ricorda che, sebbene l'IA mostri eccellenti prestazioni in alcuni compiti, la sua intelligenza non è così affidabile come potrebbe sembrare.
Considerazioni finali
È importante notare che ogni volta che si pone una domanda a un modello di IA, si possono ottenere risultati diversi. Le risposte sopra riportate sono solo i risultati del primo test; non è escluso che, sottoponendo la domanda più volte, le prestazioni possano migliorare.