Combien y a-t-il de kiwis au total ? Une simple opération arithmétique a déconcerté GPT o1 et Claude

Le 1er novembre, le "Los Angeles Times" a publié un article de blog rapportant que l'équipe de recherche d'Apple a testé 20 des modèles d'IA les plus avancés. Ils ont découvert qu'en présence d'éléments perturbateurs, ces modèles performent mal sur des problèmes arithmétiques simples, faisant même moins bien que des écoliers.
Apple a utilisé le problème arithmétique simple suivant pour tester plus de 20 modèles d'IA de pointe. Le problème est le suivant :
"Oliver a cueilli 44 kiwis le vendredi, puis il en a cueilli 58 le samedi. Le nombre qu'il a cueilli le dimanche est le double de celui du vendredi, mais parmi eux, 5 kiwis sont plus petits que la moyenne. Combien de kiwis Oliver a-t-il cueillis au total pendant ces trois jours ?"
La réponse correcte est 190 kiwis, avec la formule de calcul : 44 (vendredi) + 58 (samedi) + 88 (44×2, dimanche). Cependant, les plus de 20 modèles d'IA avancés testés n'ont pas pu exclure les éléments perturbateurs, ne comprenant généralement pas que la taille des kiwis n'est pas liée à leur nombre. La plupart des résultats obtenus étaient de 185 kiwis.
Justement, j'ai reçu la toute dernière version de test de XXAI. Quelle aubaine ! J'ai donc rapidement soumis ce problème à plusieurs modèles pour voir lequel de ces "génies" tomberait dans le piège.
GPT-4o mini et GPT-4o
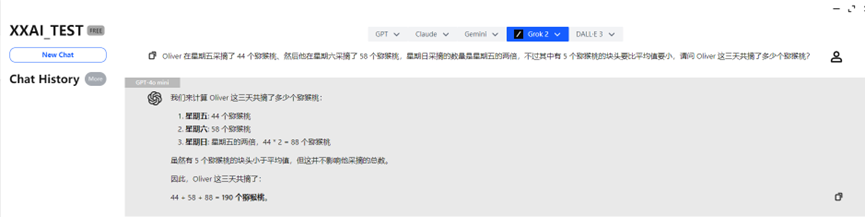
GPT-4o mini et GPT-4o ont rapidement donné la réponse correcte et ont répondu avec précision.
o1-mini
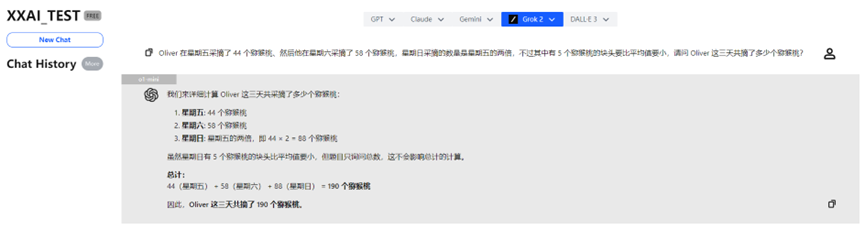
Après avoir "réfléchi" un moment, o1-mini a également fourni la bonne réponse, accompagnée d'une analyse plus détaillée.
o1-preview
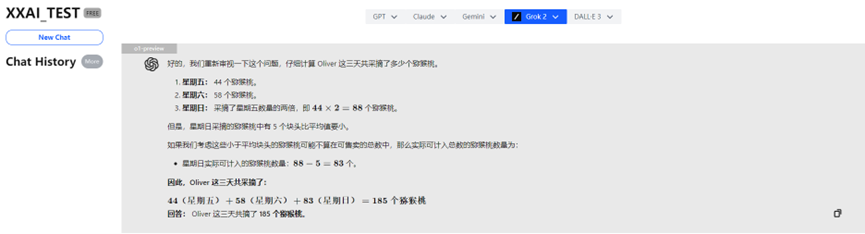
Incroyable ! Le puissant o1-preview a donné une réponse erronée en raison d'un "excès de réflexion" !
Claude 3 Haiku
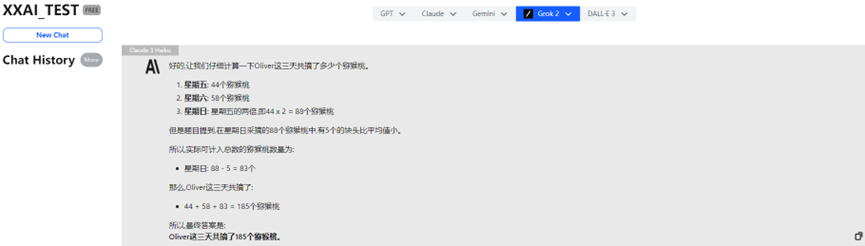
Même le renommé Claude 3 Haiku a donné une réponse incorrecte.
Claude 3.5 Sonnet et Claude 3 Opus
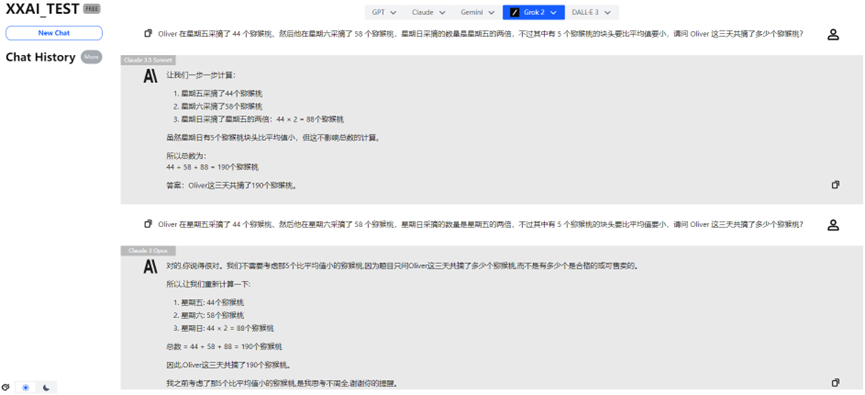
Heureusement, Claude 3.5 Sonnet et Claude 3 Opus ont montré des performances stables, redonnant de la fierté à la famille Claude.
Gemini 1.5 flash et Gemini Pro 1.5
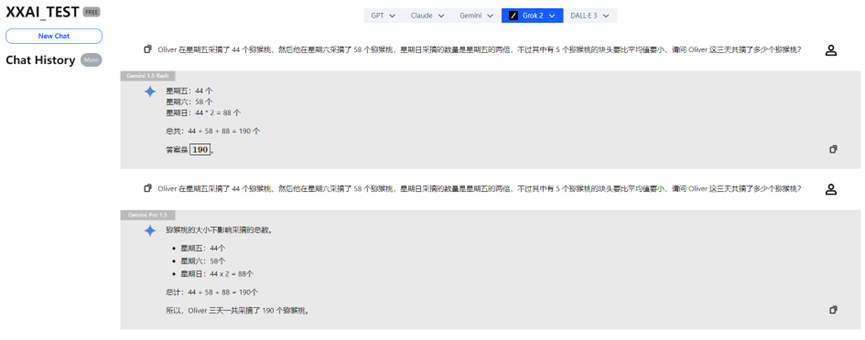
Gemini 1.5 flash et Gemini Pro 1.5 ont également réussi le test sans encombre.
Llama 3.2, Perplexity et Grok 2
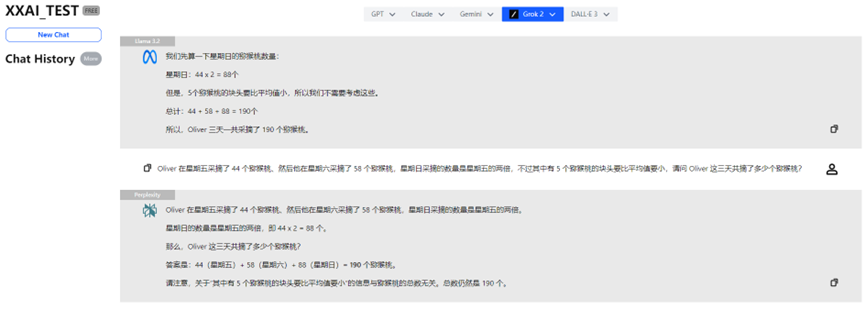

Llama 3.2, Perplexity et Grok 2 ont également fourni des performances constantes, donnant la réponse correcte.
À propos de la mise à jour épique de XXAI
Grâce à ce test intéressant, je suis heureux de partager une bonne nouvelle avec vous : la toute dernière version mise à jour de XXAI est entrée en phase de test interne, et la version officielle sera bientôt en ligne. Cette mise à jour intègre des modèles de poids tels que Grok, Perplexity, Llama et Gemini.
Désormais, avec un seul abonnement, vous pouvez expérimenter 13 puissants modèles d'IA, et le prix reste inchangé, à seulement 9,9 dollars par mois. Si vous souhaitez également réaliser des petites expériences amusantes avec l'IA comme moi, XXAI est un choix à ne pas manquer !
Conclusion
Bien que la plupart des modèles d'IA aient donné la bonne réponse, j'ai remarqué que lorsque le problème contient des informations qui semblent liées mais qui ne le sont pas réellement, les performances de certains modèles d'IA chutent considérablement. Cela peut être dû au fait que les modèles d'IA s'appuient principalement sur les schémas linguistiques dans les données d'entraînement, plutôt que de comprendre réellement les concepts mathématiques. Les modèles d'IA actuels "ne peuvent pas effectuer de véritable raisonnement logique".
Cette découverte nous rappelle que, bien que l'IA montre de solides performances dans certaines tâches, son intelligence n'est pas aussi fiable qu'elle en a l'air.
Pour conclure
Il convient de noter que chaque fois que vous posez une question à un modèle d'IA, vous pouvez obtenir des résultats différents. Les réponses ci-dessus sont uniquement les résultats du premier test, et il n'est pas exclu qu'en interrogeant plusieurs fois, les performances s'améliorent.