Llama 3.2: Vereinfachung der Anwendung von KI in der realen Welt

Kürzlich hat XXAI seine Plattform aktualisiert und fortschrittliche KI-Modelle wie Llama 3.2 integriert. Viele Leute fragen sich, wie man diese leistungsstarken KI-Modelle effektiv in praktischen Anwendungen nutzen kann und welche spezifischen Vorteile jedes Modell bietet. Um diese Fragen zu beantworten, habe ich die neuesten Informationen zu diesen KI-Modellen untersucht und evaluiert. In diesem Artikel gebe ich eine detaillierte Einführung in Llama 3.2 und teile einige Eindrücke basierend auf meiner Erfahrung.
Der neueste Release von Meta, Llama 3.2, ist nicht nur ein Update eines Sprachmodells; es ist ein bedeutender Schritt hin zu multimodalen KI-Systemen. Llama 3.2 kombiniert textuelle und visuelle Fähigkeiten und führt vier neue Modelle ein: zwei leichte Textmodelle (1B und 3B) und zwei visuelle Modelle (11B und 90B). Diese Modelle verdeutlichen die breite Anpassungsfähigkeit von Llama 3.2 in KI-Anwendungen und bieten Lösungen für Aufgaben, die von der Synthese längerer Dokumente bis hin zum komplexen Verständnis von Bildern reichen.
Übergang zu einem Multimodalen System
Mit der rasanten Entwicklung der KI-Technologie werden multimodale Systeme immer alltäglicher. Llama 3.2 ist in der Lage, sowohl Text als auch Bilder zu verarbeiten und verwirklicht somit die interdisziplinären Fähigkeiten der KI. Früher konnten KI-Modelle nur Text oder Bilder separat bearbeiten. Llama 3.2 jedoch verstärkt die Multitasking-Fähigkeiten der KI, indem es die Verarbeitung von Sprache und Bildern integriert. Zum Beispiel kann Llama 3.2 lange Artikel lesen und gleichzeitig den Bildinhalt analysieren, wodurch es wie ein Assistent handelt, der Karten versteht und mit dir kommuniziert.
Leichte Textmodelle von Llama 3.2
Die beiden leichten Textmodelle von Llama 3.2 (1B und 3B) sind darauf ausgelegt, effizient zu sein und eine große Menge an kontextuellen Informationen auf lokalen Geräten zu verarbeiten. Zum Beispiel kann das Modell 3B bis zu 128.000 Token gleichzeitig verarbeiten. Das bedeutet, dass die leichten Modelle Aufgaben wie die Zusammenfassung von Dokumenten und das Umschreiben von Inhalten ausführen können, ohne stark auf leistungsstarke Computerressourcen angewiesen zu sein.
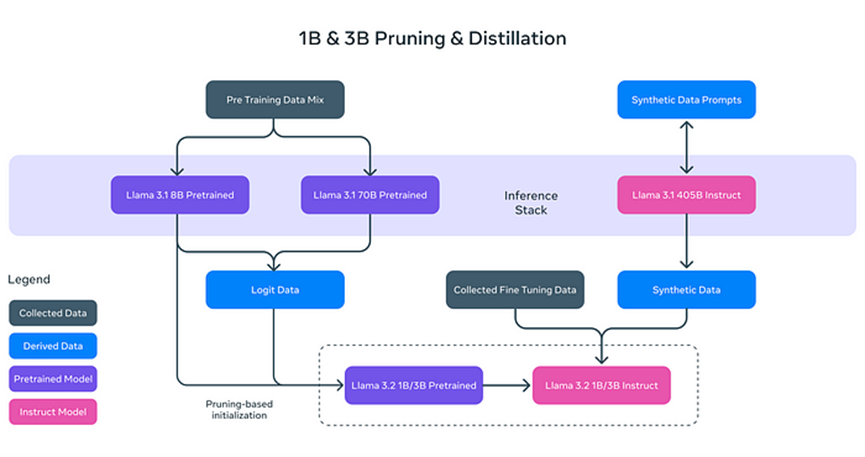
Warum sind die Textmodelle von Llama 3.2 "leicht"? Es geht nicht nur darum, die Größe des Modells zu reduzieren, sondern auch seine Effizienz durch innovative Techniken zu steigern:
- **Pruning (Abschneiden):** Entfernt die nicht wesentlichen Teile des Modells und behält gleichzeitig dessen Leistung und Effizienz bei, ähnlich wie das Beschneiden von Ästen eines Baumes für ein gesünderes und effizienteres Wachstum.
- **Distillation (Destillation):** Extrahiert und komprimiert das Wissen aus großen Modellen (wie dem 8B von Llama 3.1) in kleinere Modelle, wodurch sichergestellt wird, dass die wesentlichen Informationen erhalten bleiben.
Diese leichten Modelle verbessern nicht nur die Verarbeitungsgeschwindigkeit, sondern ermöglichen es auch Llama 3.2, auf Geräten wie Smartphones und PCs zu arbeiten und die Hardwareanforderungen für KI-Anwendungen erheblich zu reduzieren.
Nachtraining: Feineinstellung und Ausrichtung
Nach dem Pruning und der Distillation durchlaufen die Textmodelle von Llama 3.2 eine Nachtrainingsoptimierung, um ihre Leistung bei realen Aufgaben zu verbessern. Dazu gehören:
- **Supervised Fine Tuning (SFT):** Das Modell lernt detailliert, wie es bei verschiedenen Aufgaben, wie der Dokumentensynthese und Textübersetzung, präziser wird.
- **Rejection Sampling (RS):** Es werden mehrere mögliche Antworten generiert und die qualitativ beste ausgewählt.
- **Direct Preference Optimization (DPO):** Die generierten Antworten werden gemäß den Vorlieben des Benutzers sortiert, um passendere Antworten bereitzustellen.
Diese Nachtrainingsschritte ermöglichen es Llama 3.2, komplexe Textaufgaben zu bewältigen und die passendsten Antworten für unterschiedliche Probleme zu liefern.
Visuelle Fähigkeiten von Llama 3.2
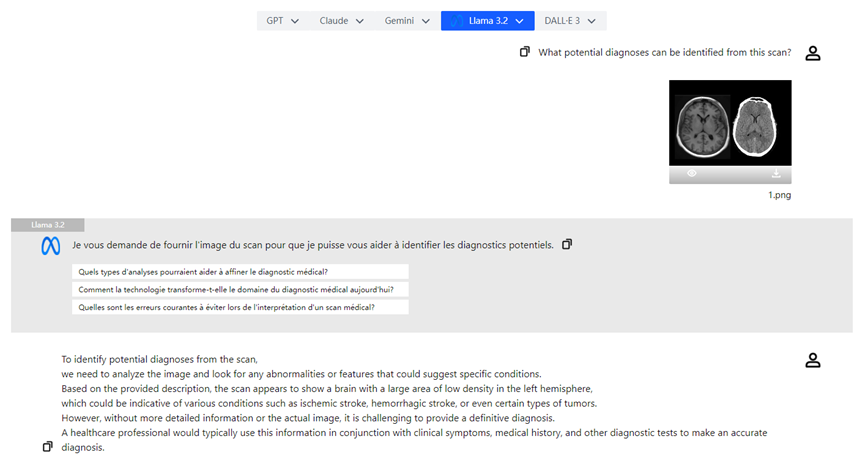
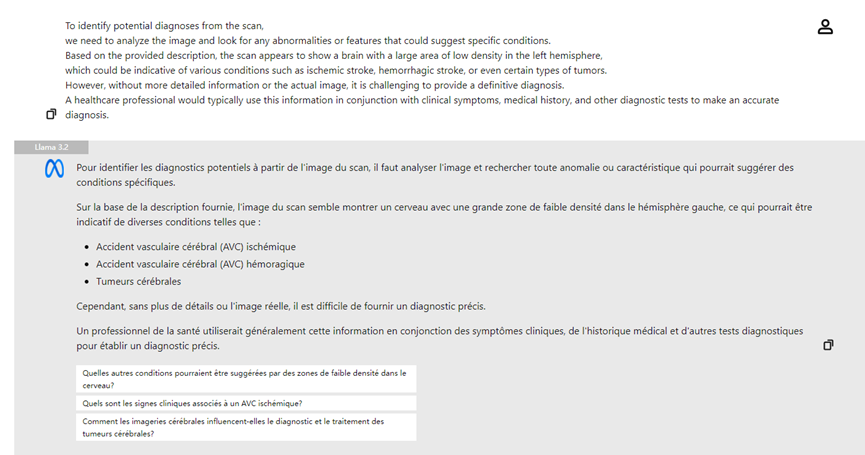
Ein weiteres herausragendes Merkmal von Llama 3.2 sind seine leistungsstarken visuellen Modelle. Mit der Einführung der Modelle 11B und 90B kann Llama 3.2 Bildinhalte ebenso wie Text analysieren und interpretieren. Zum Beispiel kann Llama 3.2 komplexe visuelle Informationen in Bildern erkennen und "visuelle Lokalisierung" basierend auf Beschreibungen durchführen. Diese Fähigkeit ist besonders nützlich in Bereichen wie Medizin und Bildung.
Das visuelle Modell von Llama 3.2 nutzt die Technologie der **Adaptergewichte (Adapter Weights)**, die eine nahtlose Integration zwischen Bildencodern und Sprachmodellen ermöglicht. Dadurch kann Llama 3.2 gleichzeitig Text und Bilder verstehen und beide Quellen zur Argumentation verwenden. Zum Beispiel kann ein Benutzer ein Foto eines Restaurantmenüs hochladen und Llama 3.2 kann die relevanten Gerichte entsprechend den Präferenzen des Benutzers (wie "vegetarisch") hervorheben.
Vergleich mit Anderen Multimodalen Modellen
Der offene Quellcode und die Anpassungsfähigkeit von Llama 3.2 verleihen ihm eine einzigartige Position auf dem Markt. Im Vergleich zu GPT von OpenAI, das ebenfalls Text- und Bildverarbeitung unterstützt, bietet Llama 3.2 eine größere Flexibilität, da die multimodalen Versionen von GPT in der Regel geschlossen sind und nicht einfach anpassbar sind. Während PixTral von Mistral relativ leicht ist, zeigt sich Llama 3.2 dennoch überlegen in Bezug auf Flexibilität und Anpassungsfähigkeit.
Llama 3.2 kann nicht nur Text- und Bildaufgaben verwalten, sondern auch fein auf die Bedürfnisse des Benutzers abgestimmt werden und erfüllt so die Anforderungen an personalisierte Anwendungen.
Anwendungsszenarien in der Realität
Die multimodalen Fähigkeiten von Llama 3.2 zeigen ein erhebliches Potenzial in verschiedenen Bereichen:
- **Dokumentensynthese:** Dank seiner leichten Textmodelle kann Llama 3.2 schnell große Mengen an Dokumenten oder PDFs zusammenfassen und die wichtigsten Informationen extrahieren.
- **Bildbeschreibung:** Llama 3.2 kann automatisch genaue Bildunterschriften generieren und den Benutzern helfen, den visuellen Inhalt besser zu verstehen.
- **Analyse medizinischer Bilder:** Ärzte können Röntgenbilder hochladen und das visuelle Modell von Llama 3.2 kann bei der Analyse helfen, potenzielle Problembereiche hervorheben und die Diagnoseeffizienz verbessern.
Fazit
Llama 3.2 stellt einen großen Fortschritt in der Technologie der künstlichen Intelligenz dar. Durch die Verbesserung der Verarbeitungs- und Effizienzgeschwindigkeit mit leichten Textmodellen und das Erzielen multimodaler Schlussfolgerungen mit visuellen Modellen vereinfachen diese Innovationen die täglichen Aufgaben weiter und erschließen das enorme Potenzial der KI in verschiedenen Branchen. Die Einführung von Llama 3.2 macht KI-Technologie zugänglicher und bietet eine breite Palette von Anwendungsszenarien, von der Dokumentensynthese bis zum Verständnis von Bildern. Mit der kontinuierlichen Entwicklung der KI-Technologie besteht kein Zweifel, dass Llama 3.2 in verschiedenen Sektoren eine zunehmend wichtige Rolle spielen wird.