谷歌 Gemini 1.5 AI 模型再升级:成本更低、性能更强、响应更快


谷歌的Gemini 1.5 AI模型在升级更新方面得到了显著的提升,推出了两款全新的模型:Gemini-1.5- pro -002和Gemini-1.5- flash -002。这些新机型不仅提高了输出的质量和效率,让用户获得更准确、高效的服务,而且显著降低了使用成本,使其在经济性方面更具竞争力。此外,这些更新为用户提供了更高的速率限制,使用户在处理大量数据时体验更流畅、更快。总体而言,Gemini 1.5的更新不仅提升了AI模型的性能,还为用户创造了更大的价值。
Gemini 1.5 AI模型再升级的简要介绍

功能再提升
Gemini-1.5-Pro-002
- 可以无缝分析、分类和总结给定提示中的大量内容。
- 可以针对不同模态(包括视频)执行高度复杂的理解和推理任务。
- 可以跨较长的代码块执行更相关的问题解决任务。
- 可以在上下文窗口增大的情况下保持较高的性能水平。
Gemini-1.5-Flash-002

- 视觉信息查找:使用外部知识结合从输入图像或视频中提取的信息来回答问题。
- 物体识别:回答与图像和视频中物体的细粒度识别相关的问题。
- 数字内容理解:回答问题并从信息图表、图表、图形、表格和网页等视觉内容中提取信息。
- 结构化内容生成:根据 HTML 和 JSON 等格式的多模式输入生成响应。
- 字幕和描述:生成具有不同细节级别的图像和视频描述。
- 推理:无需记忆或检索,即可组合推断新信息。
- 音频:分析语音文件以进行总结、转录和问答
- 多模式处理:同时处理多种类型的输入媒体,例如视频和音频输入
系统配置再升级
过滤器再优化
构建安全可靠的模型一直是的重点。借助 Gemini 的最新版本,Gemini团队改进了模型在兼顾安全性的同时遵循用户指令的能力。并且将继续提供一套安全过滤器,供开发者应用于 Google 的模型。对于今天发布的模型,默认情况下不会应用这些过滤器,以便开发者可以确定最适合其用例的配置。
Gemini 1.5 Flash-8B Experimental 改进
我们将发布 8 月份发布的 Gemini 1.5 模型的进一步改进版本,名为“Gemini-1.5-Flash-8B-Exp-0924”。此改进版本在文本和多模式用例方面均有显著的性能提升。现在可通过 Google AI Studio 和 Gemini API 使用它。
Gemini 1.5 AI 模型再升级后的优势
速率限制高
Gemini-1.5-Pro-002 和 Gemini-1.5-Flash-002 AI 型号还将提供更高的速率限制。速率限制是用户的每日使用限制。使用 1.5 Flash 型号,用户每分钟将获得 2,000 个请求 (RPM),而 1.5 Pro 型号将提供 1,000 个 RPM。
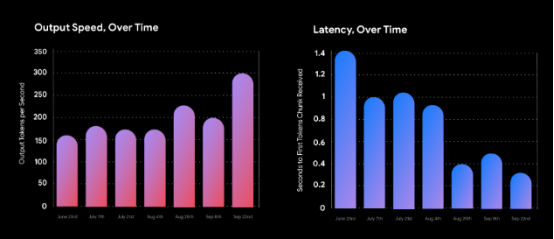
输出速度高,延迟减少
除了对最新模型进行核心改进之外,在过去几周内,我们还通过 1.5 Flash 降低了延迟,并显著提高了每秒的输出令牌数,从而利用我们最强大的模型实现了新的用例。
性能更强
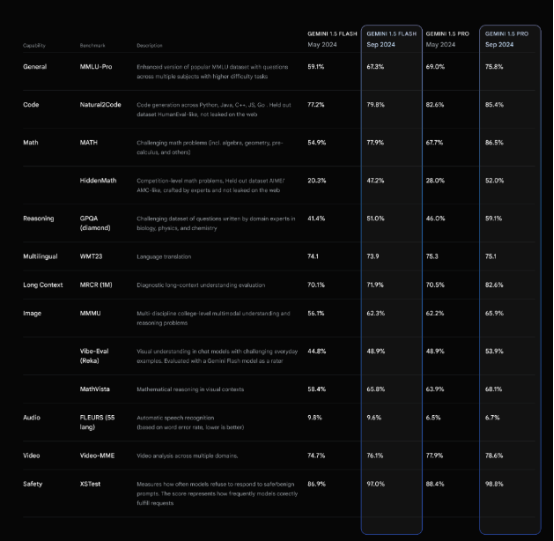
在更具挑战性的 MMLU-Pro 基准测试中,模型的性能提高了约 7%。在 MATH 和 HiddenMath 基准测试中,数学性能显著提高了 20%。视觉和代码相关任务也有所改进,在视觉理解和 Python 代码生成评估中提高了 2-7%。
成本更低
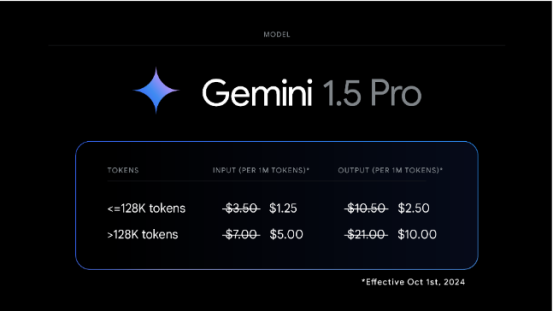
最强大的 1.5 系列型号 Gemini 1.5 Pro,输入 token 降价 64%,输出 token 降价 52%,增量缓存 token 降价 64%,,适用于少于 128K token 的提示。再加上上下文缓存,这将继续降低使用 Gemini 构建的成本。和配置Claude3.5、GPT、dalle3多种模型、功能强大的XXAI一样,相比其他的模型使用成本更低,价格极具竞争性。


其它改进
谷歌还升级了 8 月发布的 Gemini 1.5 实验模型,推出了 Gemini-1.5-Flash-8B-Exp-0924 升级版,文本和多模态应用进一步增强。用户可以通过 Google AI Studio、Gemini API 和 Vertex AI访问新的 Gemini 模型。
Conclusion
Gemini 1.5 系列模型专为在各种文本、代码和多模式任务中实现一般性能而设计。Gemini 1.5 模型的持续进步目的在于为人们、开发人员和企业使用人工智能创造、发现和构建开辟新的可能性。使 Gemini 1.5 能够更快地学习复杂任务并保持质量,同时提高训练和服务效率。总的来说,模型的整体素质提高,数学、长远背景和视野方面进步较大。