Llama 3.2:简化 AI 在实际应用中的应用

最近,XXAI更新了新的版本,将Llama3.2等AI模型集成到了应用当中,有很多人可能会有困惑了,虽然XXAI集成了那么多强大的AI模型,可是该在实际应用中如何使用它们呢?它们各自的优势又在哪里?关于这些问题,我也是第一时间做了功课,查阅了关于这些AI模型的相关介绍资料并且做了一番测评,这篇文章我将会对Llama3.2做详细的介绍以及一些使用感受。
Meta最新发布的Llama 3.2,它不仅仅是一个语言模型的更新,更是人工智能技术向多模态系统迈出的重要一步。Llama 3.2集成了文本与视觉能力,推出了四个全新的模型:两个轻量化文本模型(1B和3B)和两个视觉模型(11B和90B)。这些模型的推出标志着Llama 3.2在AI应用领域的广泛适应性,从长文档总结到复杂图像理解,Llama 3.2为多种实际任务提供了解决方案。
向多模态系统的转变
随着AI技术的快速发展,多模态系统逐渐成为主流。Llama 3.2不仅能够处理文本,还能理解和推理图像,真正实现了AI的跨领域能力。过去的AI模型只能分别处理文本或图像,但Llama 3.2通过融合语言与视觉处理能力,赋予了AI更强的多任务处理能力。举个例子,Llama 3.2可以同时读取长篇文章并分析图片内容,像一个能够同时理解地图并与您对话的助手。
Llama 3.2的这种多模态特性,已与GPT的多模态变体、Mistral的PixTral等模型共同成为市场的佼佼者。它们不仅能处理文本和图像,还能实现二者的结合,为更加复杂的应用场景提供支持。
Llama 3.2的轻量化文本模型
Llama 3.2的两个轻量化文本模型(1B和3B)经过优化设计,既小巧又高效,能够在本地设备上处理大量的上下文信息。以3B模型为例,它能够同时处理多达128,000个tokens的数据。这意味着,Llama 3.2的轻量化模型能够高效地执行任务,如文档总结、内容重写等,而无需过多依赖强大的计算资源。
什么让Llama 3.2的文本模型如此“轻量”?
Llama 3.2的轻量化并非简单的减少模型规模,而是通过创新的技术手段提高了模型的效率。具体来说,Llama 3.2通过以下两种技术实现了轻量化:
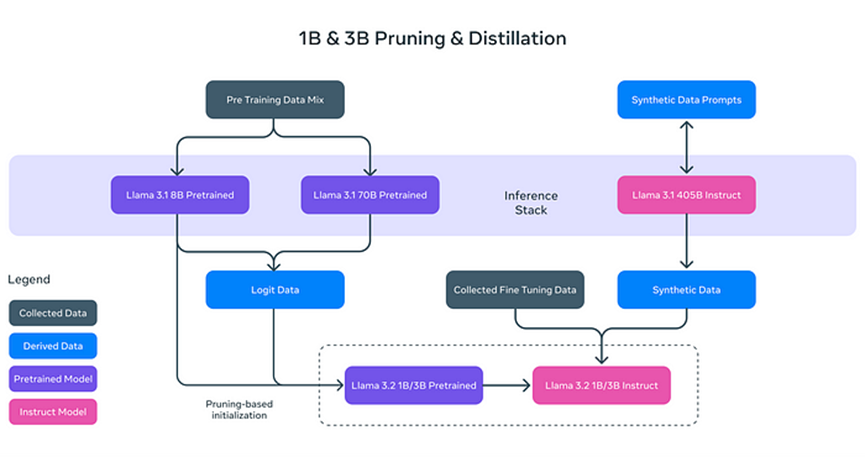
- 剪枝(Pruning):移除模型中不重要的部分,同时保持其性能和效率,类似于修剪树木枝条,使其更加健康和高效。
- 蒸馏(Distillation):将大模型(如Llama 3.1的8B)中的知识提取并压缩到更小的模型中,确保核心信息不丢失。
这些轻量化的模型不仅提升了处理速度,也使得Llama 3.2可以在设备如智能手机和个人电脑上运行,极大降低了AI应用的硬件要求。
后训练:精细调整和对齐
Llama 3.2的文本模型在经过剪枝和蒸馏后,还进行了后训练优化,以提高其在实际任务中的表现。这包括:
- 监督微调(SFT):模型通过细致的指导,学习如何在不同的任务中表现得更加准确,比如文档摘要和文本翻译。
- 拒绝采样(RS):通过生成多个可能的答案,系统筛选出质量最优的回应。
- 直接偏好优化(DPO):根据用户的偏好,对生成的答案进行排名,提供更符合需求的回答。
这些后训练步骤让Llama 3.2不仅能处理复杂的文本任务,还能在面对不同问题时给出最合适的答案。
Llama 3.2的视觉能力
Llama 3.2的另一个亮点是其强大的视觉模型。通过引入11B和90B模型,Llama 3.2不仅能理解文本,还能分析图片和图像内容。例如,Llama 3.2可以识别图片中的复杂视觉信息,并基于描述进行“视觉定位”。这一能力使得Llama 3.2能够在医学、教育等领域提供强大的支持。
Llama 3.2的视觉模型采用了**适配器权重(Adapter Weights)**技术,使得图像编码器和语言模型之间能够无缝对接。这使得Llama 3.2能够同时理解文本和图像,并结合两者的信息进行推理。例如,用户可以上传一张餐馆菜单的照片,Llama 3.2根据用户的偏好(如“素食”)高亮出相关菜品。
与其他多模态模型的比较
Llama 3.2的开放源码和定制化能力使它在市场上占据了独特的地位。与OpenAI的GPT相比,GPT的多模态版本虽然也支持文本和图像处理,但通常是闭源的,无法轻松进行定制和微调。而Mistral的PixTral则相对较轻,但Llama 3.2在灵活性和定制性方面仍然具备优势。Llama 3.2不仅支持文本和图像任务的处理,还能根据用户的需求进行微调,满足个性化应用的需求。
实际应用场景
Llama 3.2的多模态能力在多个领域展示了其强大的潜力:
- 文档摘要:通过轻量化文本模型,Llama 3.2可以帮助快速总结大量文档或PDF文件,提取关键信息。
- 图像描述:Llama 3.2可以自动生成准确的图像标题,帮助用户更好地理解视觉内容。
- 医学图像分析:医生可以上传X光片,Llama 3.2的视觉模型可以辅助分析,突出可能的病变区域,提升诊断效率。
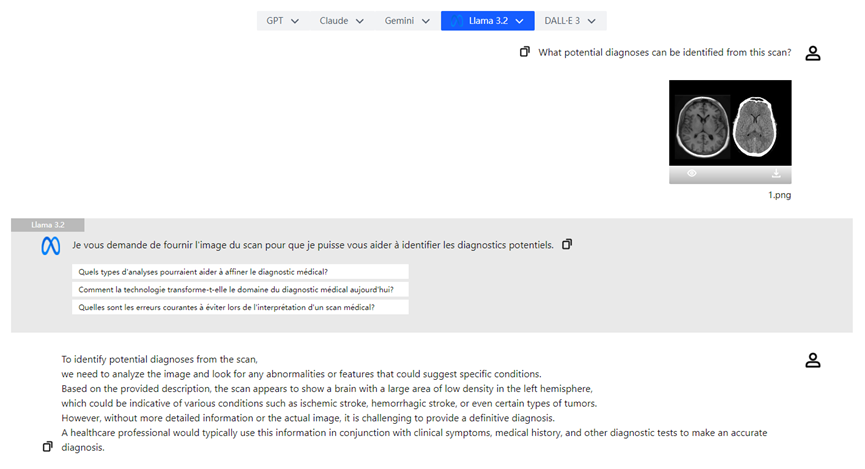
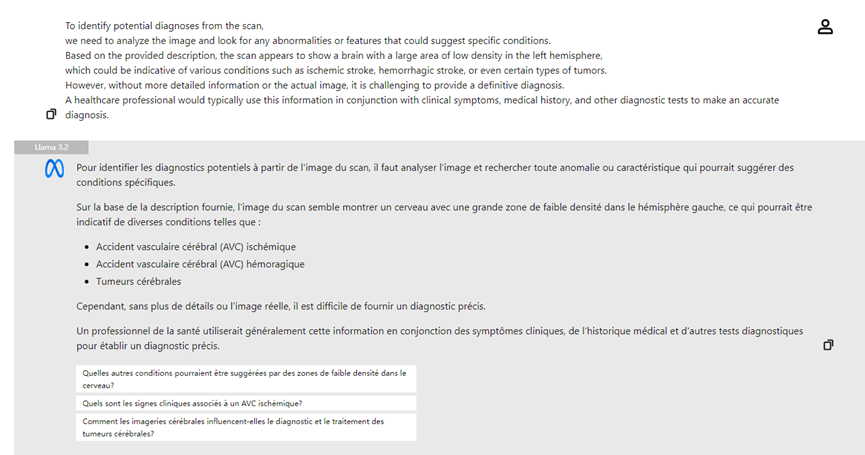
结论
Llama 3.2代表了人工智能技术的一大进步。它不仅通过轻量化文本模型提高了处理速度和效率,还通过视觉模型实现了图文结合的多模态推理。这些创新将进一步简化日常任务,帮助各行业解锁AI的巨大潜力。
Llama 3.2的推出使得AI技术更加普及,带来了从文档摘要到图像理解等广泛应用场景。随着AI技术的不断发展,Llama 3.2无疑将在各个行业中发挥越来越重要的作用。