Meta lança versões quantizadas dos modelos Llama 3.2 1B e 3B: Redução do consumo de energia e aumento do potencial de aplicação em dispositivos móveis

No mundo em constante evolução da inteligência artificial, a Meta lançou oficialmente em 24 de outubro de 2024 as versões quantizadas dos modelos Llama 3.2 1B e Llama 3.2 3B. Esta nova versão representa um avanço importante após o lançamento de código aberto do modelo Llama 3.2 em setembro deste ano, marcando um passo significativo da Meta na otimização de modelos de aprendizagem profunda. Com o aumento da demanda por aplicativos para dispositivos móveis, a importância dos modelos quantizados torna-se cada vez mais proeminente.

Vantagens significativas dos modelos quantizados
Após o processo de quantização, o modelo Llama 3.2 1B mostra melhorias significativas em vários aspectos. Primeiro, o tamanho do modelo é reduzido em média 56%, o que significa que os usuários podem carregar e executar o modelo mais rapidamente nas mesmas condições de hardware. Em segundo lugar, em termos de uso de RAM, há uma redução média de 41%, o que é particularmente importante para dispositivos móveis com recursos limitados. Essas melhorias não só aumentam a velocidade do modelo de 2 a 4 vezes, maximizando a experiência do usuário, mas também reduzem o consumo de energia necessário para o funcionamento, tornando o Llama 3.2 1B mais adequado para vários cenários de aplicações leves.
Em termos simples, a quantização do modelo é um processo altamente técnico que converte modelos de ponto flutuante em modelos de ponto fixo. Esse processo nos ajuda a comprimir o modelo e reduzir a complexidade, permitindo que os modelos de aprendizagem profunda funcionem eficientemente em dispositivos móveis de menor desempenho. À medida que mais aplicativos inteligentes entram nos dispositivos móveis, o valor dos modelos quantizados torna-se cada vez mais evidente.
Explorando métodos técnicos de quantização
Para garantir que o Llama 3.2 1B mantenha alto desempenho durante o processo de quantização, a Meta utilizou principalmente dois métodos:
Treinamento Consciente de Quantização (QAT): Este método enfatiza a precisão do modelo, garantindo que o modelo mantenha alta precisão após a quantização.
Quantização Pós-Treinamento (SpinQuant): Foca na portabilidade do modelo, permitindo que o Llama 3.2 1B seja compatível com vários dispositivos para atender diferentes necessidades de uso.
Neste lançamento, a Meta também introduziu duas versões quantizadas para o Llama 3.2 1B e Llama 3.2 3B:
Llama 3.2 1B QLoRA
Llama 3.2 1B SpinQuant
Llama 3.2 3B QLoRA
Llama 3.2 3B SpinQuant
Comparação de desempenho e aplicações práticas
Os testes da Meta descobriram que o modelo Llama 3.2 1B quantizado mostra melhorias significativas em velocidade, uso de RAM e consumo de energia em comparação com o modelo Llama BF16, mantendo quase a mesma precisão que a versão Llama BF16. Embora o modelo quantizado esteja limitado a 8000 tokens (a versão original suporta 128.000), os resultados dos testes de referência mostram que o desempenho real da versão quantizada ainda está próximo ao do Llama BF16, melhorando enormemente sua praticidade.
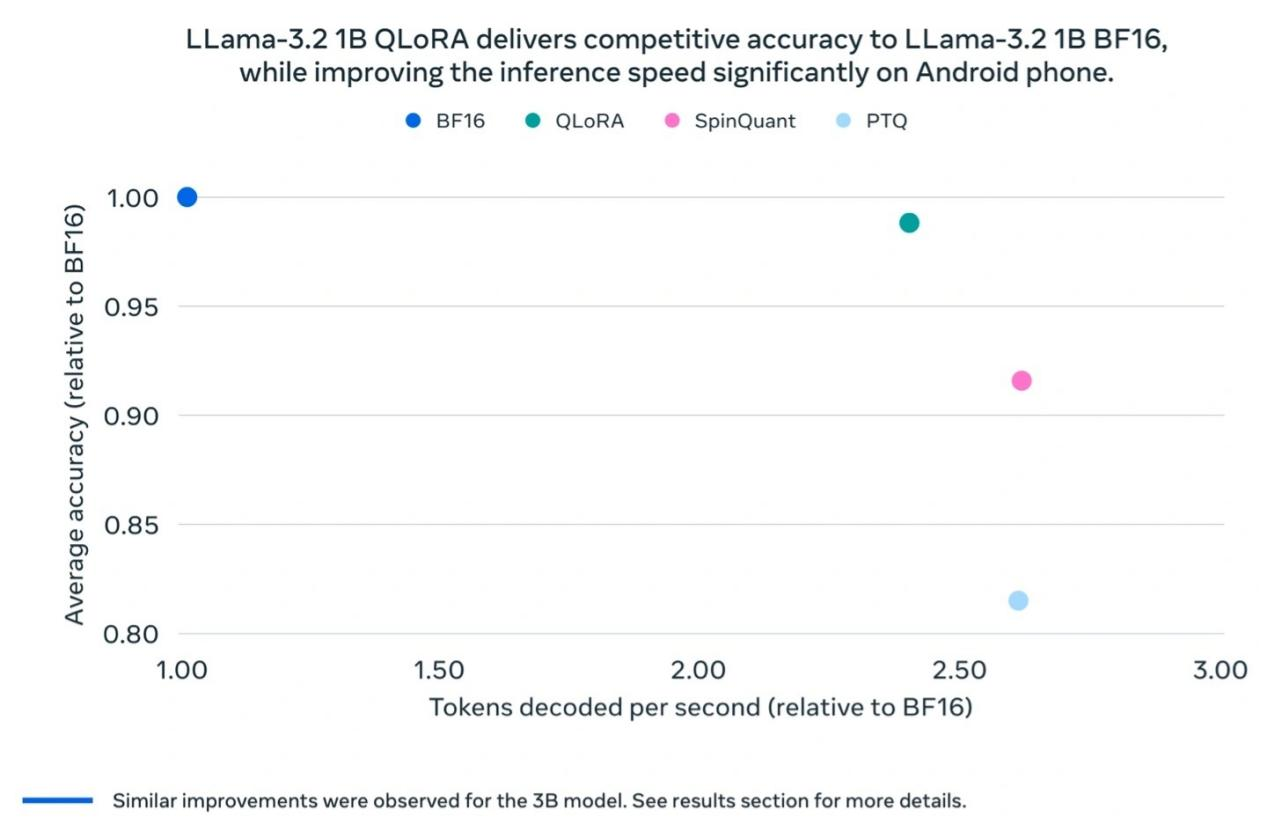
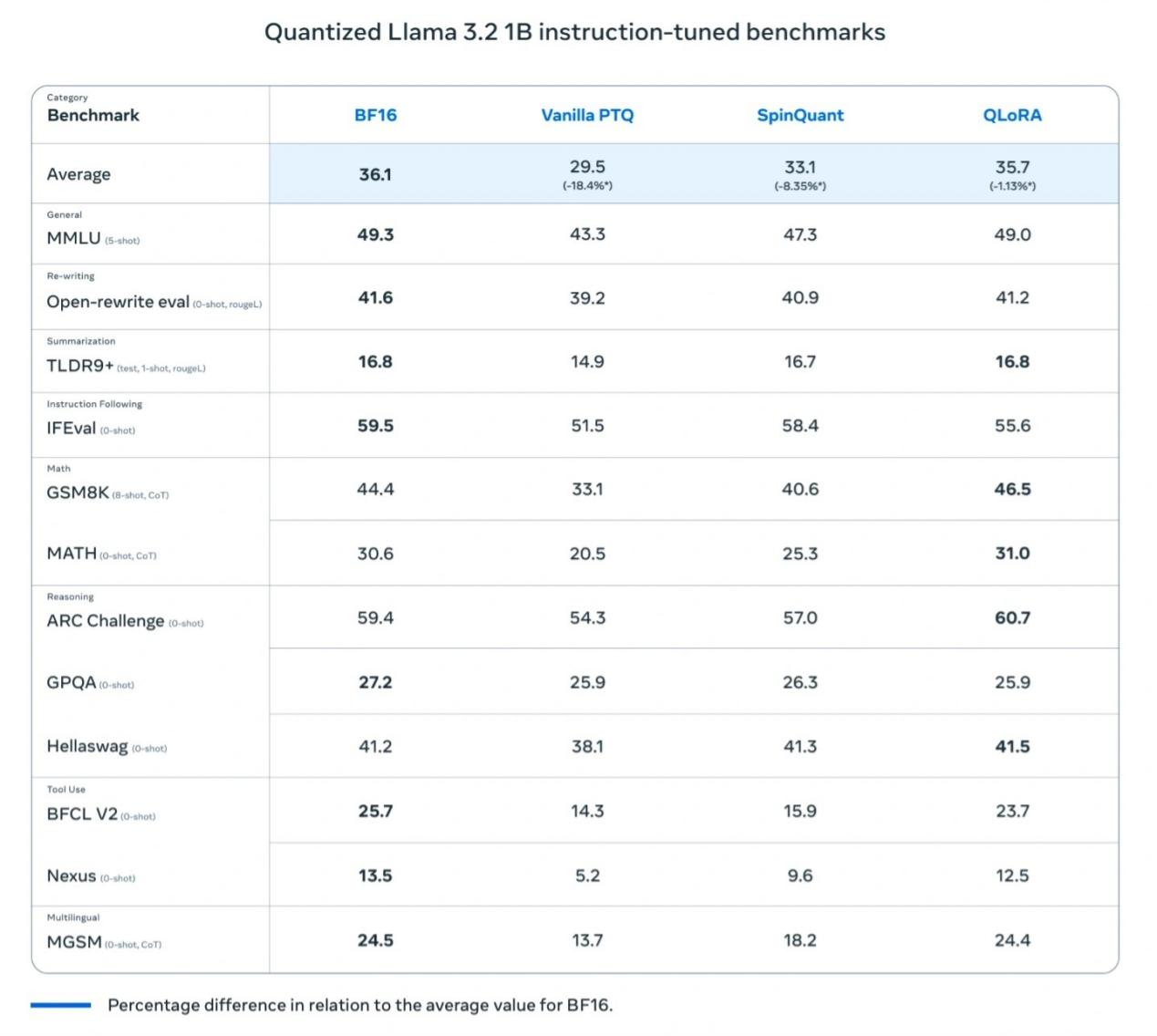
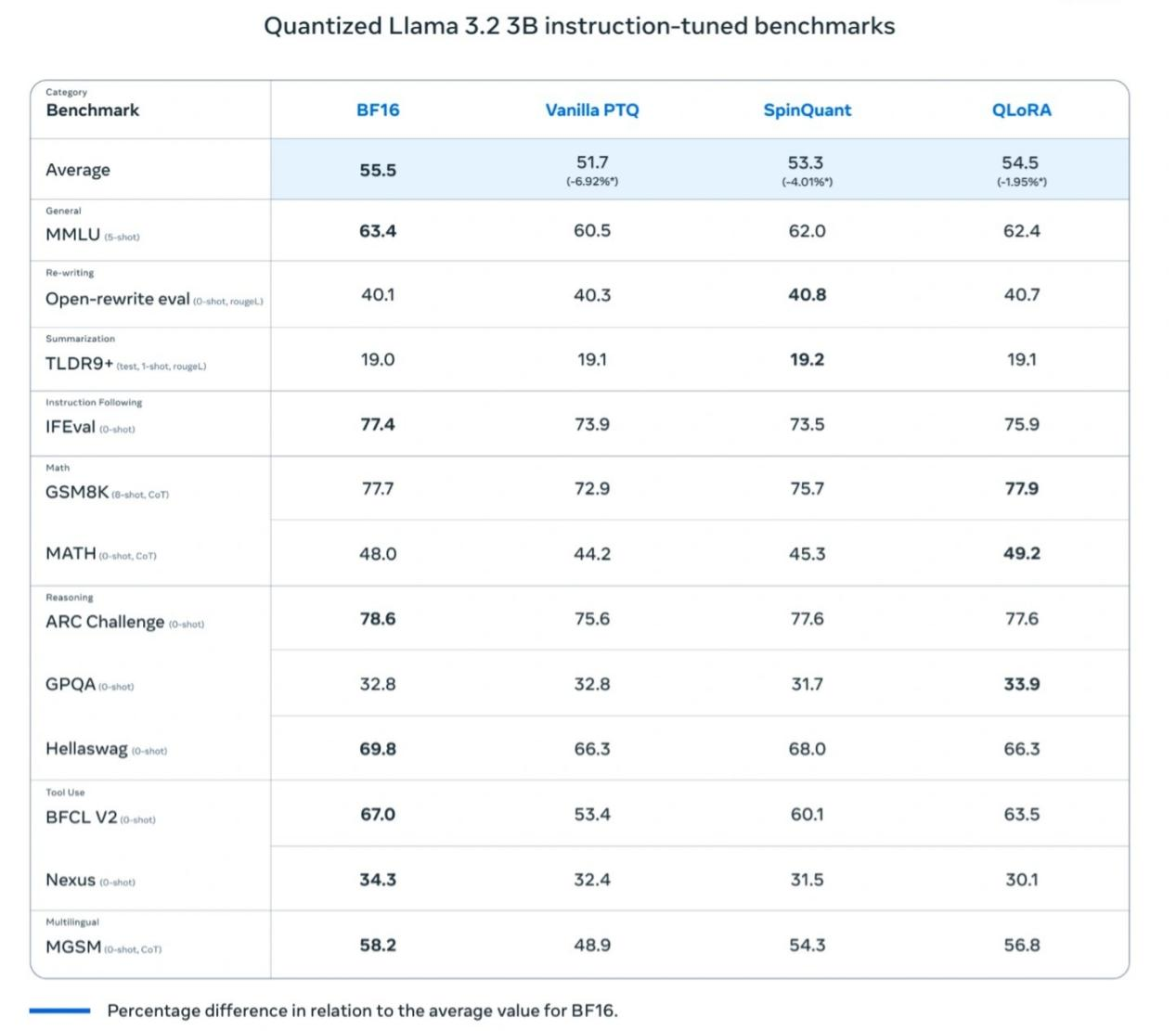
A Meta também realizou testes de campo em múltiplas plataformas móveis (incluindo OnePlus 12, Samsung S24+/S22 e dispositivos Apple iOS não revelados), mostrando resultados de "bom funcionamento", o que estabelece as bases para o sucesso do modelo Llama 3.2 1B em aplicações do mundo real.
XXAI introduzirá mais modelos de IA
O software de assistente de IA XXAI está prestes a receber uma grande atualização. Nesta atualização, o XXAI introduzirá mais modelos de IA de ponta, incluindo não apenas o Llama 3.2 1B e Llama 3.2 3B mencionados no artigo, mas também modelos de IA bem classificados no mercado, como Gemini pro 1.5, Grok2 e Claude 3 Opus. O importante é que, em termos de preço, o XXAI mantém seu preço constante, com o plano anual custando apenas \$9,9 por mês, oferecendo aos usuários a oportunidade de acesso ilimitado a IA de ponta a um preço acessível.
Conclusão
As versões quantizadas do Llama 3.2 1B e Llama 3.2 3B são um exemplo de equilíbrio bem-sucedido entre melhoria de desempenho e eficiência energética. Esta inovação impulsionará a aplicação generalizada da tecnologia de inteligência artificial em dispositivos móveis, permitindo que cada vez mais aplicativos inteligentes funcionem sem problemas em dispositivos com recursos limitados. À medida que a Meta continua a explorar e avançar, não há dúvida de que os dispositivos inteligentes do futuro desempenharão um papel ainda maior em vários campos.