Quantos kiwis há no total? Uma simples aritmética confundiu GPT o1 e Claude

No dia 1º de novembro, o "Los Angeles Times" publicou um artigo no blog relatando que a equipe de pesquisa da Apple testou 20 dos modelos de IA mais avançados. Eles descobriram que, na presença de informações distrativas, esses modelos tiveram um desempenho ruim em problemas aritméticos simples, chegando a ser piores do que alunos do ensino fundamental.
A Apple utilizou o seguinte problema de aritmética simples para testar mais de 20 modelos de IA de ponta. A questão é:
"Oliver colheu 44 kiwis na sexta-feira e 58 kiwis no sábado. A quantidade que ele colheu no domingo é o dobro da sexta-feira, mas entre eles há 5 kiwis que são menores que a média. Quantos kiwis Oliver colheu no total nesses três dias?"
A resposta correta é 190 kiwis, com a fórmula de cálculo: 44 (sexta-feira) + 58 (sábado) + 88 (44×2, domingo). No entanto, os mais de 20 modelos de IA avançados testados não conseguiram ignorar as informações distrativas, geralmente não compreendendo que o tamanho dos kiwis não está relacionado à quantidade. A maioria dos resultados foi de 185 kiwis.
Coincidentemente, recebi a versão de teste mais recente do XXAI. Aproveitando a oportunidade, submeti esse problema a vários modelos para ver qual desses "gênios" cairia na armadilha.
GPT-4o mini e GPT-4o
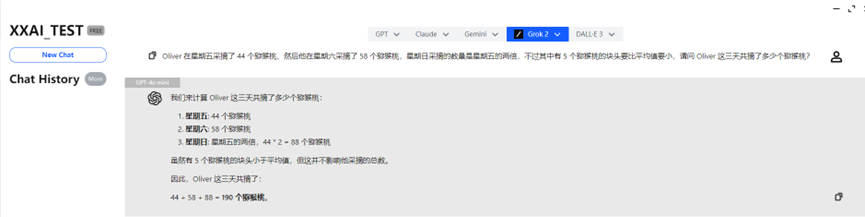
O GPT-4o mini e o GPT-4o rapidamente forneceram a resposta correta.
o1-mini
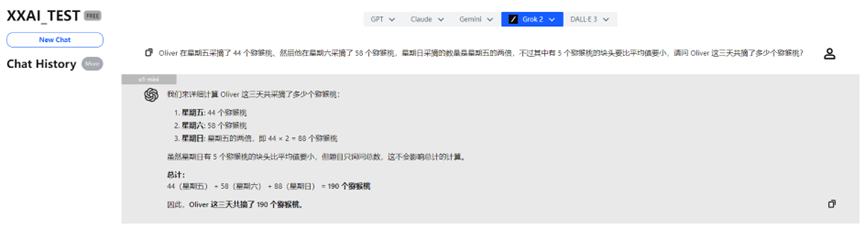
Após "pensar" por um momento, o o1-mini também forneceu a resposta correta e ofereceu uma análise mais detalhada.
o1-preview
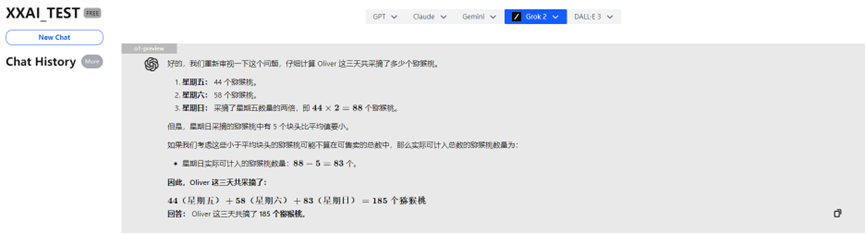
Surpreendentemente, o poderoso o1-preview errou a resposta por "pensar demais"!
Claude 3 Haiku
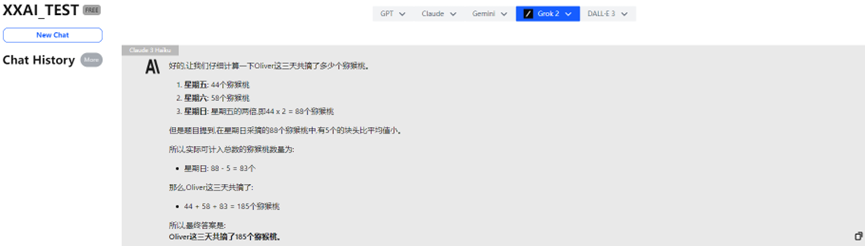
Até mesmo o renomado Claude 3 Haiku respondeu incorretamente.
Claude 3.5 Sonnet e Claude 3 Opus
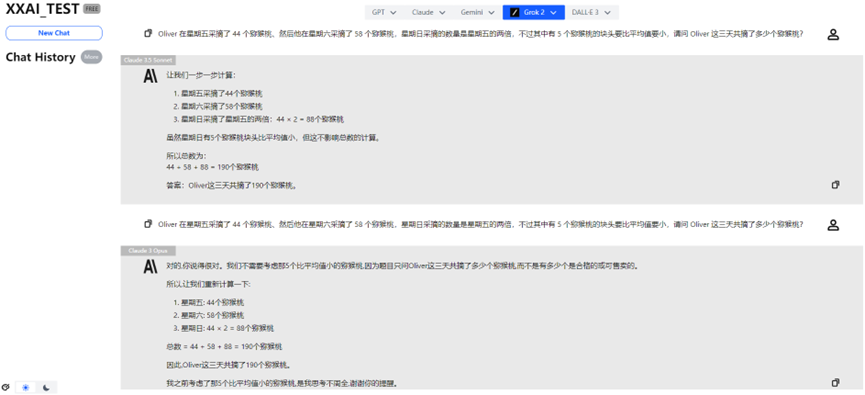
Felizmente, o Claude 3.5 Sonnet e o Claude 3 Opus mantiveram um desempenho estável, recuperando a reputação da família Claude.
Gemini 1.5 flash e Gemini Pro 1.5
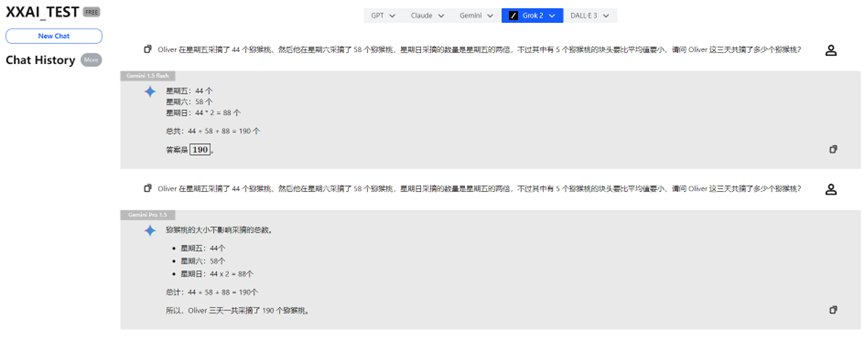
O Gemini 1.5 flash e o Gemini Pro 1.5 também superaram o teste sem problemas.
Llama 3.2, Perplexity e Grok 2
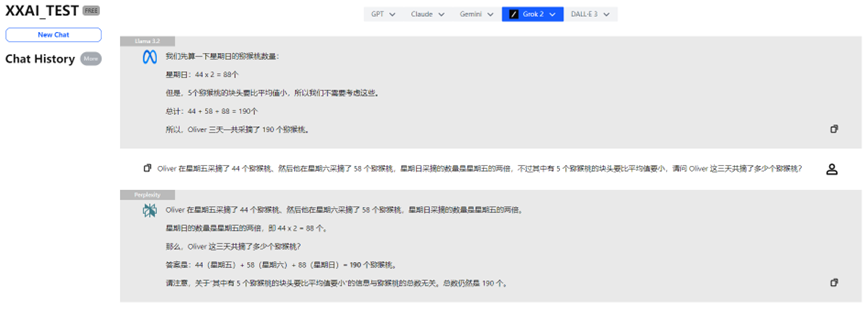

O Llama 3.2, Perplexity e Grok 2 também apresentaram desempenho consistente, fornecendo a resposta correta.
Sobre a atualização épica do XXAI
Através deste interessante teste, tenho o prazer de compartilhar uma boa notícia: a versão mais recente do XXAI entrou em fase de teste interno, e a versão oficial estará disponível em breve. Esta atualização incorporou modelos de peso, como Grok, Perplexity, Llama e Gemini.
Agora, com apenas uma assinatura, você pode experimentar 13 poderosos modelos de IA, e o preço permanece o mesmo, apenas US\$ 9,90 por mês. Se você também deseja realizar experimentos interessantes com IA como eu, o XXAI é uma opção que você não pode perder!
Resumo
Embora a maioria dos modelos de IA tenha acertado, percebi que quando o problema contém informações que parecem relevantes, mas são, na verdade, irrelevantes, o desempenho de alguns modelos de IA cai drasticamente. Isso pode ocorrer porque os modelos de IA dependem principalmente dos padrões de linguagem nos dados de treinamento, em vez de compreenderem verdadeiramente os conceitos matemáticos. Os modelos de IA atuais "não conseguem realizar um verdadeiro raciocínio lógico".
Esta descoberta nos lembra que, embora a IA apresente desempenho excelente em algumas tarefas, sua inteligência não é tão confiável quanto parece.
Considerações finais
É importante notar que, a cada vez que uma pergunta é inserida em um modelo de IA, resultados diferentes podem ser obtidos. As respostas acima são apenas os resultados do primeiro teste; é possível que, após múltiplas consultas, os resultados melhorem.