Meta rilascia versioni quantizzate dei modelli Llama 3.2 1B e 3B: Riduzione del consumo energetico e aumento del potenziale di applicazione su dispositivi mobili

Nel mondo in rapida evoluzione dell'intelligenza artificiale, Meta ha ufficialmente rilasciato il 24 ottobre 2024 le versioni quantizzate dei modelli Llama 3.2 1B e Llama 3.2 3B. Questa nuova versione rappresenta un importante progresso dopo il rilascio open source del modello Llama 3.2 di settembre di quest'anno, segnando un ulteriore passo avanti di Meta nell'ottimizzazione dei modelli di apprendimento profondo. Con l'aumento della domanda di applicazioni per dispositivi mobili, l'importanza dei modelli quantizzati diventa sempre più evidente.

Vantaggi significativi dei modelli quantizzati
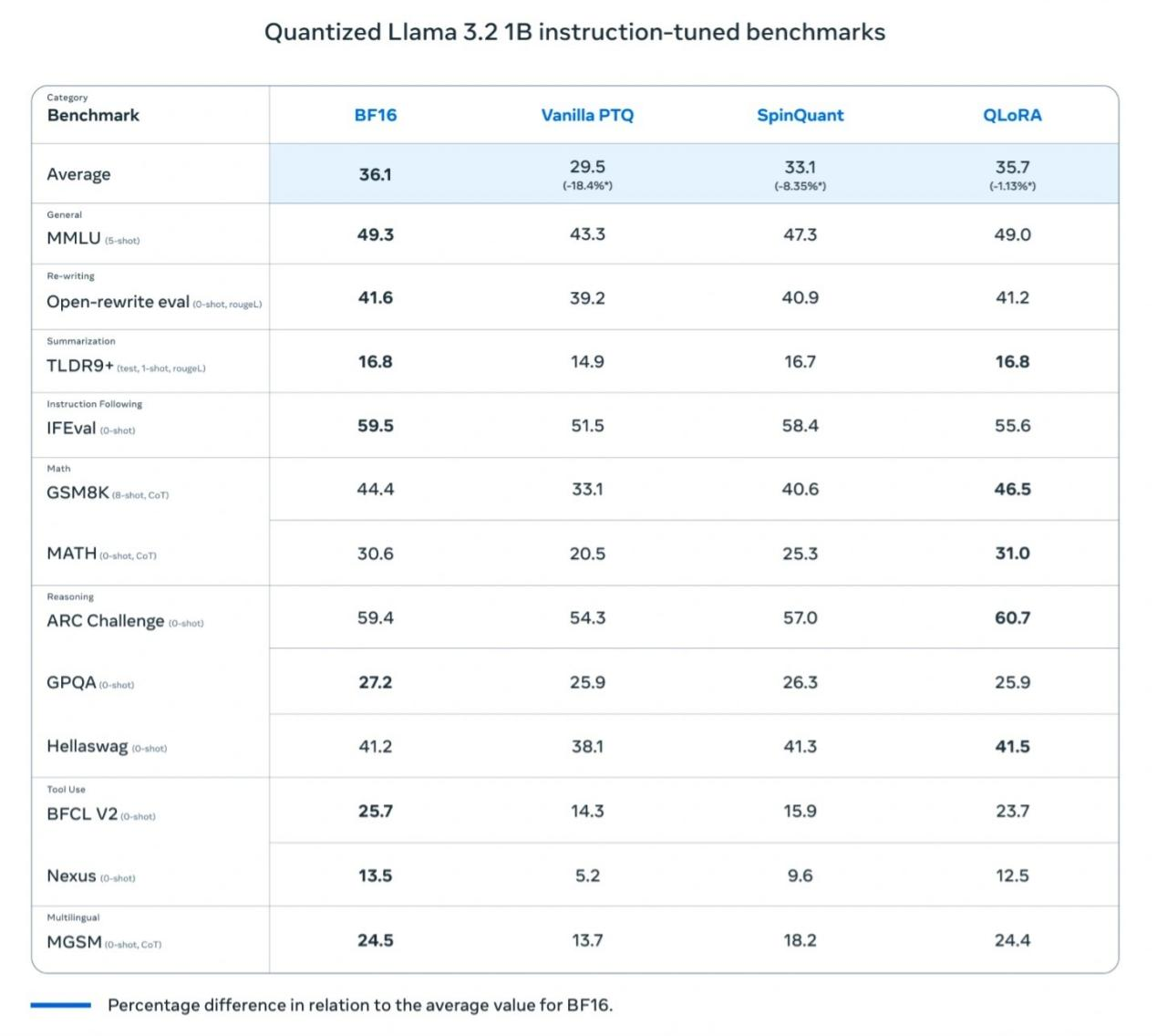
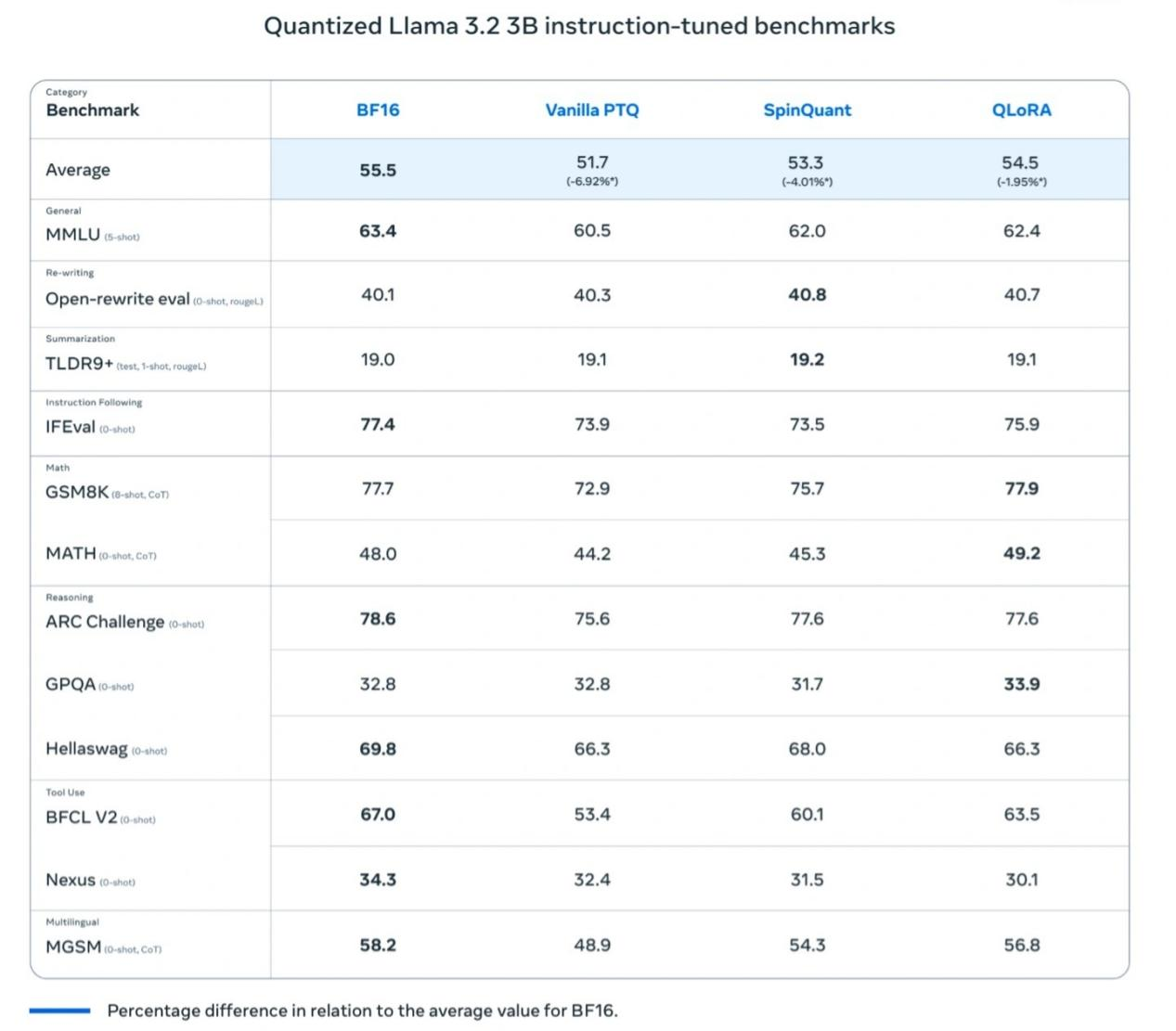
Dopo il processo di quantizzazione, il modello Llama 3.2 1B mostra miglioramenti significativi in vari aspetti. In primo luogo, la dimensione del modello è ridotta in media del 56%, il che significa che gli utenti possono caricare ed eseguire il modello più rapidamente nelle stesse condizioni hardware. In secondo luogo, in termini di utilizzo della RAM, c'è una riduzione media del 41%, particolarmente importante per i dispositivi mobili con risorse limitate. Questi miglioramenti non solo aumentano la velocità del modello da 2 a 4 volte, massimizzando l'esperienza dell'utente, ma riducono anche il consumo energetico necessario per il funzionamento, rendendo Llama 3.2 1B più adatto a vari scenari di applicazioni leggere.
In termini semplici, la quantizzazione del modello è un processo altamente tecnico che converte i modelli a virgola mobile in modelli a virgola fissa. Questo processo ci aiuta a comprimere il modello riducendo al contempo la complessità, consentendo ai modelli di apprendimento profondo di funzionare efficientemente su dispositivi mobili meno performanti. Con sempre più applicazioni intelligenti che entrano nei dispositivi mobili, il valore dei modelli quantizzati diventa sempre più evidente.
Esplorando metodi tecnici di quantizzazione
Per garantire che Llama 3.2 1B mantenga prestazioni elevate durante il processo di quantizzazione, Meta ha utilizzato principalmente due metodi:
Quantization-Aware Training (QAT): Questo metodo enfatizza l'accuratezza del modello, assicurando che il modello mantenga un'alta precisione dopo la quantizzazione.
Post-Training Quantization (SpinQuant): Si concentra sulla portabilità del modello, rendendo Llama 3.2 1B compatibile con vari dispositivi per soddisfare diverse esigenze d'uso.
Con questo rilascio, Meta ha anche introdotto due versioni quantizzate ciascuna per Llama 3.2 1B e Llama 3.2 3B:
Llama 3.2 1B QLoRA
Llama 3.2 1B SpinQuant
Llama 3.2 3B QLoRA
Llama 3.2 3B SpinQuant
Confronto delle prestazioni e applicazioni pratiche
I test di Meta hanno rivelato che il modello Llama 3.2 1B quantizzato mostra miglioramenti significativi in termini di velocità, utilizzo della RAM e consumo energetico rispetto al modello Llama BF16, mantenendo al contempo una precisione quasi identica alla versione Llama BF16. Sebbene il modello quantizzato sia limitato a 8000 token (la versione originale ne supporta 128.000), i risultati dei test di riferimento mostrano che le prestazioni effettive della versione quantizzata rimangono vicine a Llama BF16, migliorando notevolmente la sua praticità.
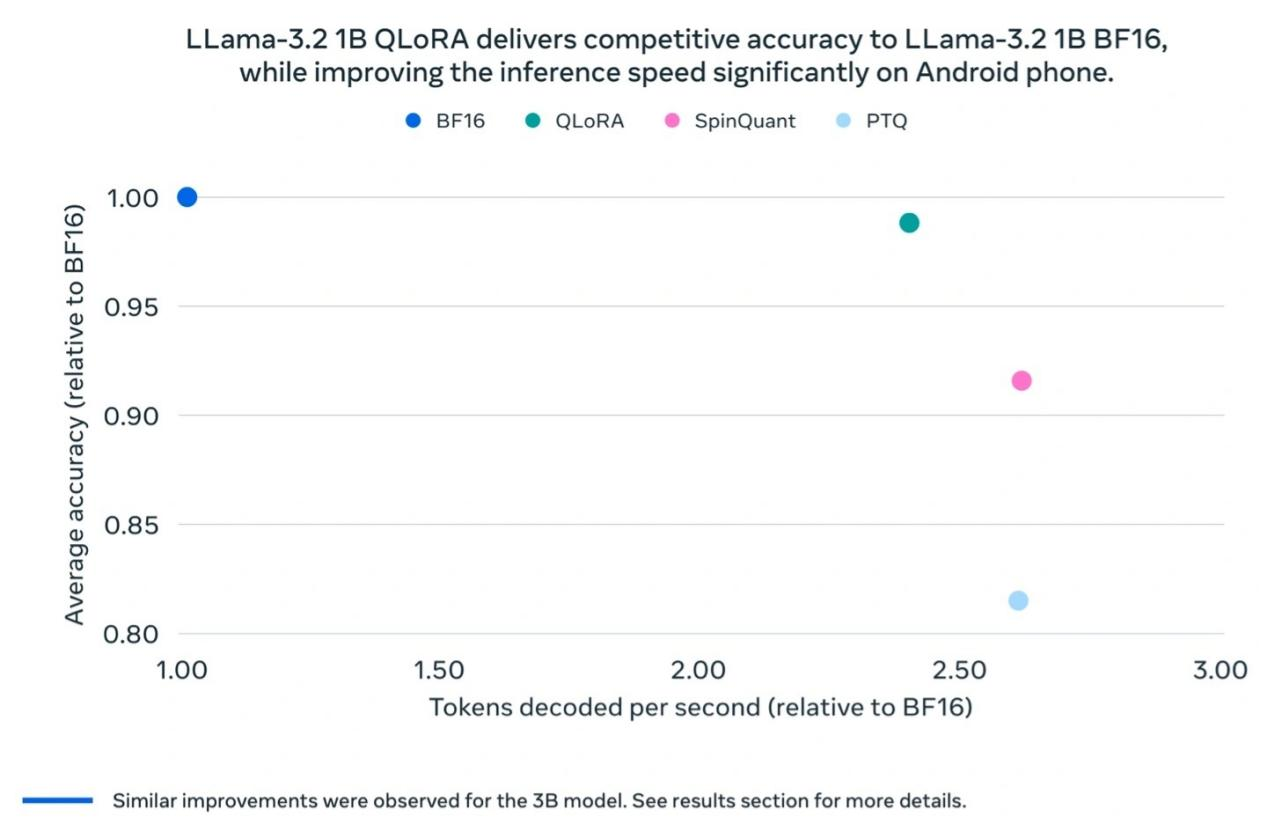
Meta ha anche condotto test sul campo su diverse piattaforme mobili (inclusi OnePlus 12, Samsung S24+/S22 e dispositivi Apple iOS non divulgati), mostrando risultati di "buon funzionamento", gettando le basi per il successo del modello Llama 3.2 1B nelle applicazioni del mondo reale.
XXAI introdurrà presto più modelli di IA
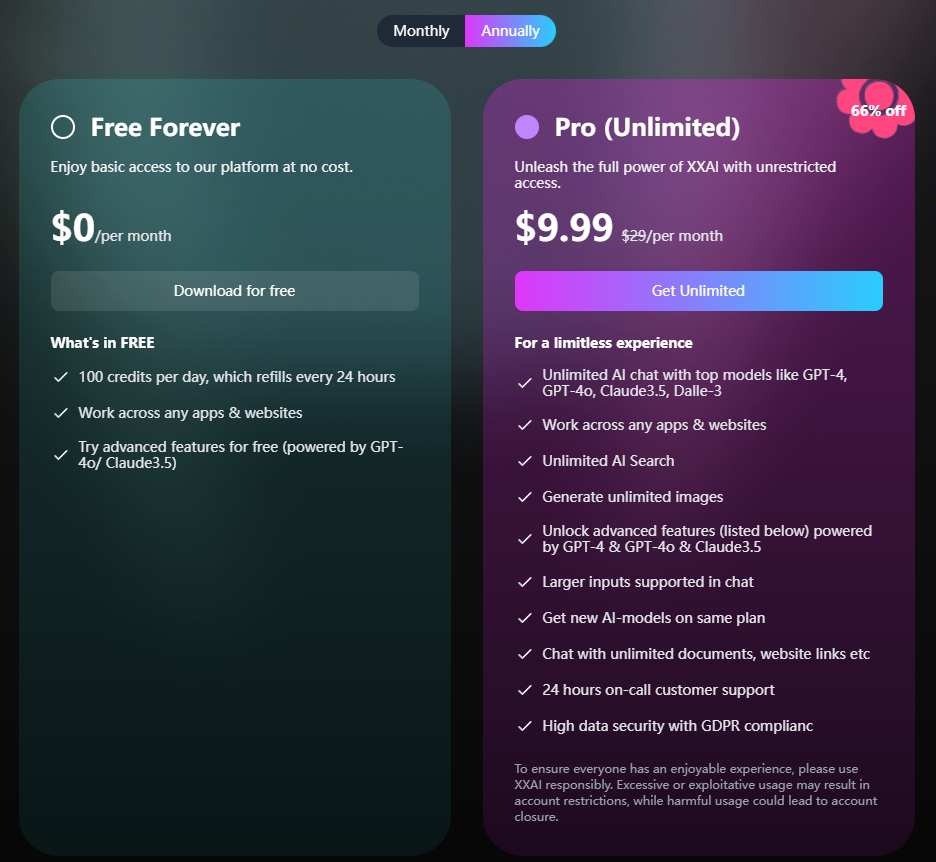
Il software di assistente IA XXAI sta per ricevere un grande aggiornamento. In questo aggiornamento, XXAI introdurrà più modelli di IA di punta, inclusi non solo Llama 3.2 1B e Llama 3.2 3B menzionati nell'articolo, ma anche modelli di IA ben classificati sul mercato come Gemini pro 1.5, Grok2 e Claude 3 Opus. Importante è che, in termini di prezzo, XXAI mantiene il suo prezzo costante, con un piano annuale che costa solo 9,9 dollari al mese, offrendo agli utenti l'opportunità di accesso illimitato all'IA di punta a un prezzo accessibile.
Conclusione
Le versioni quantizzate di Llama 3.2 1B e Llama 3.2 3B sono un esempio di successo nel bilanciamento tra miglioramento delle prestazioni ed efficienza energetica. Questa innovazione promuoverà l'ampia applicazione della tecnologia di intelligenza artificiale sui dispositivi mobili, consentendo a sempre più applicazioni intelligenti di funzionare senza problemi su dispositivi con risorse limitate. Con Meta che continua a esplorare e fare progressi, non c'è dubbio che i futuri dispositivi intelligenti giocheranno un ruolo ancora più grande in vari campi.