Llama 3.2: Semplificare l'Applicazione dell'IA nel Mondo Reale

Recentemente, XXAI ha aggiornato la sua piattaforma integrando modelli avanzati di IA come Llama 3.2. Molti si chiedono come utilizzare efficacemente questi potenti modelli di IA in applicazioni pratiche e quali vantaggi specifici offra ciascuno di essi. Per rispondere a queste domande, ho esaminato e valutato le informazioni più recenti su questi modelli di IA. In questo articolo fornirò un'introduzione dettagliata a Llama 3.2 e condividerò alcune impressioni basate sulla mia esperienza.
L'ultimo lancio di Meta, Llama 3.2, non è semplicemente un aggiornamento di un modello linguistico; rappresenta un passo significativo verso sistemi di IA multimodali. Llama 3.2 combina capacità testuali e visive, introducendo quattro nuovi modelli: due modelli di testo leggeri (1B e 3B) e due modelli visivi (11B e 90B). Questi modelli dimostrano l'ampia adattabilità di Llama 3.2 nelle applicazioni di IA, offrendo soluzioni per compiti che vanno dalla sintesi di documenti lunghi alla comprensione complessa delle immagini.
Transizione verso un Sistema Multimodale
Con lo sviluppo rapido della tecnologia IA, i sistemi multimodali stanno diventando sempre più comuni. Llama 3.2 è in grado di elaborare sia testo che immagini, realizzando appieno le capacità interdisciplinari dell'IA. In passato, i modelli di IA potevano gestire il testo o le immagini separatamente. Tuttavia, Llama 3.2 rafforza le capacità multitasking dell'IA integrando l'elaborazione del linguaggio e delle immagini. Ad esempio, Llama 3.2 può leggere articoli lunghi mentre analizza il contenuto delle immagini, agendo come un assistente in grado di comprendere mappe e dialogare con te.
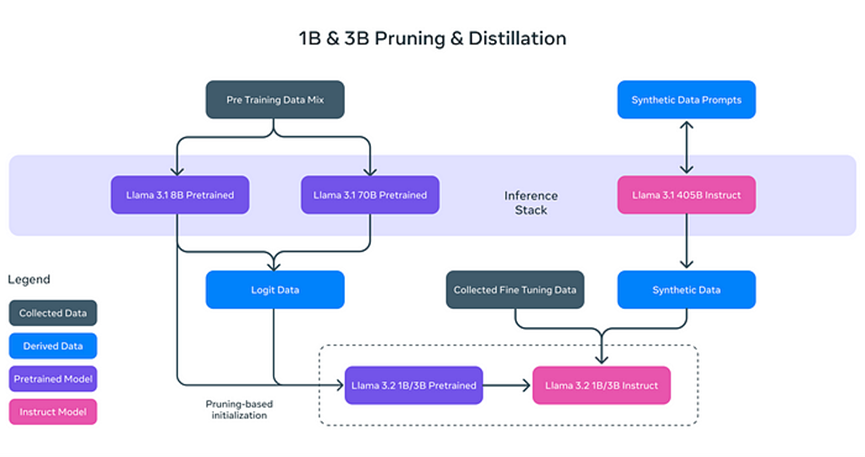
Modelli di Testo Leggeri di Llama 3.2
I due modelli di testo leggeri di Llama 3.2 (1B e 3B) sono progettati per essere efficienti e in grado di gestire una grande quantità di informazioni contestuali su dispositivi locali. Ad esempio, il modello 3B può elaborare fino a 128.000 token simultaneamente. Ciò significa che i modelli leggeri possono eseguire compiti come la sintesi di documenti e la riscrittura di contenuti senza dipendere pesantemente da risorse computazionali potenti.
Perché i modelli di testo di Llama 3.2 sono "leggeri"? Non si tratta solo di ridurre la dimensione del modello, ma di migliorarne l'efficienza attraverso tecniche innovative:
- **Pruning (Potatura):** Rimuove le parti non essenziali del modello mantenendo comunque le sue prestazioni ed efficienza, simile alla potatura dei rami di un albero per una crescita più sana ed efficiente.
- **Distillation (Distillazione):** Estrae e comprime la conoscenza da modelli grandi (come l'8B di Llama 3.1) in modelli più piccoli, assicurando che le informazioni essenziali siano mantenute.
Questi modelli leggeri migliorano non solo la velocità di elaborazione ma permettono anche a Llama 3.2 di funzionare su dispositivi come smartphone e computer personali, riducendo significativamente i requisiti hardware per le applicazioni di IA.
Post-Addestramento: Messa a Punto e Allineamento
Dopo la potatura e la distillazione, i modelli di testo di Llama 3.2 passano attraverso un'ottimizzazione post-addestramento per migliorare le loro performance nei compiti reali. Ciò include:
- **Fine Tuning Supervisionato (SFT):** Il modello apprende in modo più approfondito come migliorare la precisione in vari compiti, come la sintesi di documenti e la traduzione di testi.
- **Rejection Sampling (RS):** Genera molteplici risposte possibili e seleziona quella di migliore qualità.
- **Ottimizzazione delle Preferenze Dirette (DPO):** Classifica le risposte generate in base alle preferenze dell'utente, fornendo risposte più adatte alle loro esigenze.
Questi passaggi di post-addestramento permettono a Llama 3.2 di gestire compiti di testo complessi e di fornire le risposte più appropriate per diversi problemi.
Capacità Visive di Llama 3.2
Un altro aspetto rilevante di Llama 3.2 sono i suoi potenti modelli visivi. Con l'introduzione dei modelli 11B e 90B, Llama 3.2 può analizzare e interpretare il contenuto delle immagini, oltre a comprendere il testo. Ad esempio, Llama 3.2 può riconoscere informazioni visive complesse nelle immagini ed eseguire "localizzazione visiva" basata su descrizioni. Questa capacità è particolarmente utile in campi come la medicina e l'educazione.
I modelli visivi di Llama 3.2 utilizzano la tecnologia dei **Pesi degli Adattatori (Adapter Weights)**, permettendo un'integrazione fluida tra encoder di immagini e modelli di linguaggio. Ciò consente a Llama 3.2 di comprendere contemporaneamente testo e immagini, e di utilizzare entrambe le fonti per ragionare. Ad esempio, un utente può caricare una foto di un menù di ristorante e Llama 3.2 può evidenziare i piatti rilevanti in base alle preferenze dell'utente (come "vegetariano").
Confronto con Altri Modelli Multimodali
Il codice sorgente aperto e la capacità di personalizzazione di Llama 3.2 gli conferiscono una posizione unica sul mercato. Rispetto al GPT di OpenAI, che supporta anch'esso l'elaborazione di testo e immagini, Llama 3.2 offre maggiore flessibilità, poiché le versioni multimodali di GPT sono generalmente a codice chiuso e non facilmente personalizzabili. Mentre il PixTral di Mistral è relativamente leggero, Llama 3.2 si dimostra ancora superiore in termini di flessibilità e capacità di personalizzazione.
Llama 3.2 non solo gestisce compiti di testo e immagine, ma può anche essere finemente regolato in base alle esigenze dell'utente, rispondendo così alle richieste di applicazioni personalizzate.
Scenari di Applicazione Reale
Le capacità multimodali di Llama 3.2 dimostrano un potenziale significativo in vari campi:
- **Sintesi di Documenti:** Grazie ai suoi modelli di testo leggeri, Llama 3.2 può riassumere rapidamente grandi quantità di documenti o file PDF, estraendo le informazioni chiave.
- **Descrizione di Immagini:** Llama 3.2 può generare automaticamente didascalie di immagini precise, aiutando gli utenti a comprendere meglio il contenuto visivo.
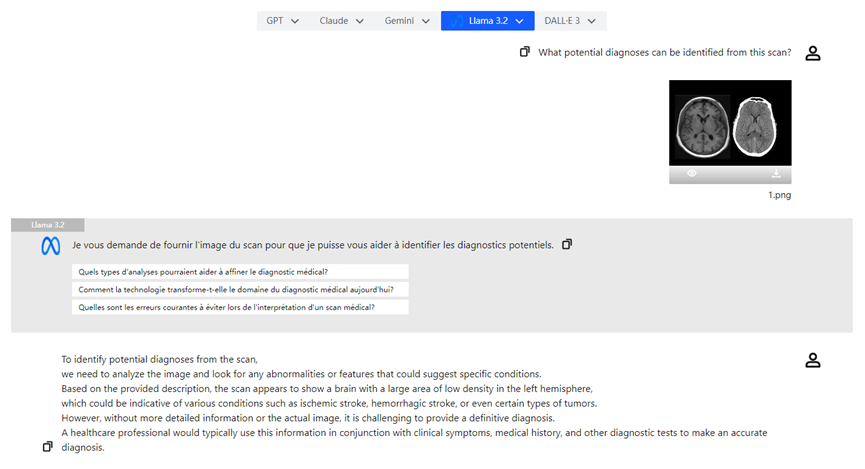
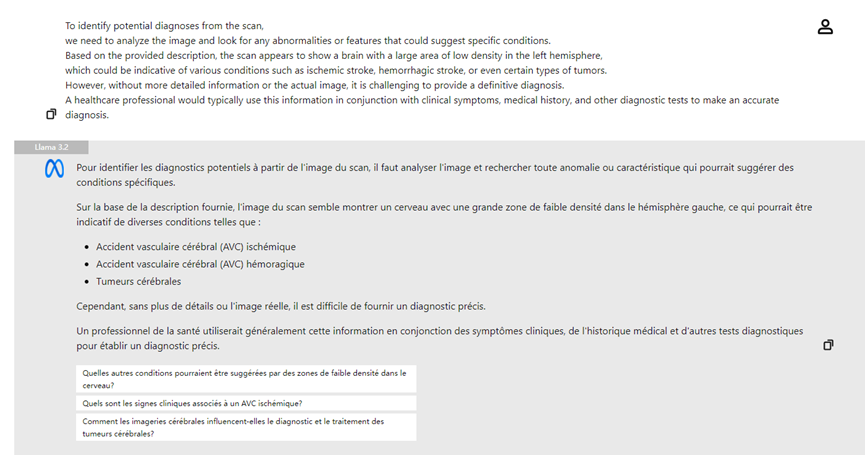
- **Analisi di Immagini Mediche:** I medici possono caricare radiografie e il modello visivo di Llama 3.2 può aiutare nell'analisi, evidenziando le aree di possibile interesse e migliorando l'efficienza diagnostica.
Conclusione
Llama 3.2 rappresenta un grande salto in avanti nel campo della tecnologia dell'intelligenza artificiale. Migliorando la velocità e l'efficienza con modelli di testo leggeri e realizzando ragionamenti multimodali con modelli visivi, queste innovazioni semplificano ulteriormente i compiti quotidiani e sbloccano il vasto potenziale dell'IA in vari settori. Il lancio di Llama 3.2 rende la tecnologia dell'IA più accessibile, offrendo un'ampia gamma di scenari di applicazione, dalla sintesi di documenti alla comprensione delle immagini. Con lo sviluppo continuo della tecnologia IA, non c'è dubbio che Llama 3.2 giocherà un ruolo sempre più importante in diversi settori.