Llama 3.2 : Simplifier l'Application de l'IA dans le Monde Réel

Récemment, XXAI a mis à jour sa plateforme en intégrant des modèles d'IA avancés tels que Llama 3.2. Beaucoup se demandent comment utiliser efficacement ces puissants modèles d'IA dans des applications pratiques et quels sont les avantages spécifiques de chacun. Pour répondre à ces questions, j'ai investigué et évalué les informations les plus récentes sur ces modèles d'IA. Dans cet article, je fournirai une introduction détaillée de Llama 3.2 et partagerai certaines de mes impressions basées sur mon expérience.
Le dernier lancement de Meta, Llama 3.2, n'est pas simplement une mise à jour d'un modèle linguistique ; c'est un pas significatif vers les systèmes d'IA multimodaux. Llama 3.2 combine des capacités textuelles et visuelles, en introduisant quatre nouveaux modèles : deux modèles de texte légers (1B et 3B) et deux modèles visuels (11B et 90B). Ces modèles illustrent l'adaptabilité étendue de Llama 3.2 dans les applications d'IA, offrant des solutions pour des tâches allant de la synthèse de documents longs à la compréhension complexe d'images.
Transition vers un Système Multimodal
Avec le développement rapide de la technologie d'IA, les systèmes multimodaux deviennent de plus en plus courants. Llama 3.2 peut traiter aussi bien le texte que les images, réalisant véritablement les capacités transdisciplinaires de l'IA. Auparavant, les modèles d'IA ne pouvaient traiter le texte ou les images séparément. Cependant, Llama 3.2 renforce les capacités multitâches de l'IA en intégrant le traitement du langage et des images. Par exemple, Llama 3.2 peut lire des articles longs tout en analysant le contenu des images, agissant comme un assistant capable de comprendre des cartes et de converser avec vous.
Modèles de Texte Légers de Llama 3.2
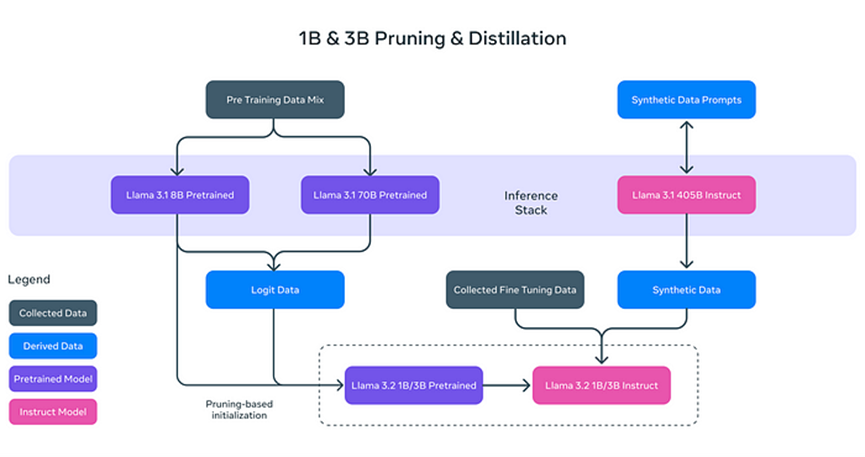
Les deux modèles de texte légers de Llama 3.2 (1B et 3B) sont conçus pour être efficaces et peuvent gérer une grande quantité d'informations contextuelles sur des appareils locaux. Par exemple, le modèle 3B peut traiter jusqu'à 128,000 tokens simultanément. Cela signifie que les modèles légers peuvent exécuter des tâches comme la synthèse de documents et la réécriture de contenu sans dépendre fortement de ressources informatiques puissantes.
Pourquoi les modèles de texte de Llama 3.2 sont-ils "légers" ? Il ne s'agit pas simplement de réduire la taille du modèle, mais d'améliorer son efficacité grâce à des techniques innovantes :
- **Élagage (Pruning) :** Cette technique élimine les parties non essentielles du modèle tout en conservant ses performances et son efficacité, semblable à l'élagage des branches d'un arbre pour une croissance plus saine et efficace.
- **Distillation :** Elle extrait et compresse les connaissances de modèles plus grands (comme le 8B de Llama 3.1) dans des modèles plus petits, garantissant que l'information essentielle est conservée.
Ces modèles légers améliorent non seulement la vitesse de traitement, mais aussi permettent à Llama 3.2 de fonctionner sur des appareils tels que des smartphones et des ordinateurs personnels, réduisant ainsi considérablement les exigences matérielles pour les applications d'IA.
Post-Formation : Réglage Fin et Alignement
Après l'élagage et la distillation, les modèles de texte de Llama 3.2 passent par une optimisation post-formation pour améliorer leurs performances dans les tâches réelles. Cela inclut :
- **Réglage Fin Supervisé (SFT) :** Le modèle apprend de manière approfondie comment faire preuve de plus de précision dans diverses tâches, telles que la synthèse de documents et la traduction de textes.
- **Échantillonnage par Rejet (RS) :** Génère de nombreuses réponses possibles et sélectionne celle de meilleure qualité.
- **Optimisation Préférentielle Directe (DPO) :** Classe les réponses générées selon les préférences de l'utilisateur, offrant des réponses mieux adaptées à leurs besoins.
Ces étapes de post-formation permettent à Llama 3.2 de gérer des tâches de texte complexes et de fournir les réponses les plus appropriées aux différents problèmes.
Capacités Visuelles de Llama 3.2
Un autre aspect saillant de Llama 3.2 est ses puissants modèles visuels. Avec l'introduction des modèles 11B et 90B, Llama 3.2 peut analyser et interpréter le contenu des images, en plus de comprendre le texte. Par exemple, Llama 3.2 peut reconnaître des informations visuelles complexes dans les images et effectuer une "localisation visuelle" basée sur des descriptions. Cette capacité est particulièrement utile dans des domaines tels que la médecine et l'éducation.
Les modèles visuels de Llama 3.2 utilisent la technologie des **Poids d'Adaptateurs (Adapter Weights)**, permettant une intégration fluide entre les encodeurs d'images et les modèles linguistiques. Cela permet à Llama 3.2 de comprendre simultanément le texte et les images, et d'utiliser les deux sources pour raisonner. Par exemple, un utilisateur peut télécharger une photo d'un menu de restaurant et Llama 3.2 peut mettre en évidence les plats pertinents en fonction des préférences de l'utilisateur (comme "végétarien").
Comparaison avec d'Autres Modèles Multimodaux
Le code source ouvert et la capacité de personnalisation de Llama 3.2 lui confèrent une position unique sur le marché. Comparé au GPT d'OpenAI, qui prend également en charge le traitement du texte et des images, Llama 3.2 offre plus de flexibilité, car les versions multimodales de GPT sont généralement à code source fermé et ne sont pas facilement personnalisables. Alors que le PixTral de Mistral est relativement léger, Llama 3.2 se montre encore supérieur en termes de flexibilité et de capacité de personnalisation.
Llama 3.2 ne se contente pas de gérer des tâches de texte et d'image, mais peut également être ajusté finement selon les besoins de l'utilisateur, répondant ainsi aux demandes d'applications personnalisées.
Scénarios d'Application Réelle
Les capacités multimodales de Llama 3.2 démontrent un potentiel significatif dans divers domaines :
- **Synthèse de Documents :** Grâce à ses modèles de texte légers, Llama 3.2 peut résumer rapidement de grandes quantités de documents ou de fichiers PDF, extrayant les informations clés.
- **Description d'Images :** Llama 3.2 peut générer automatiquement des sous-titres d'images précis, aidant les utilisateurs à mieux comprendre le contenu visuel.
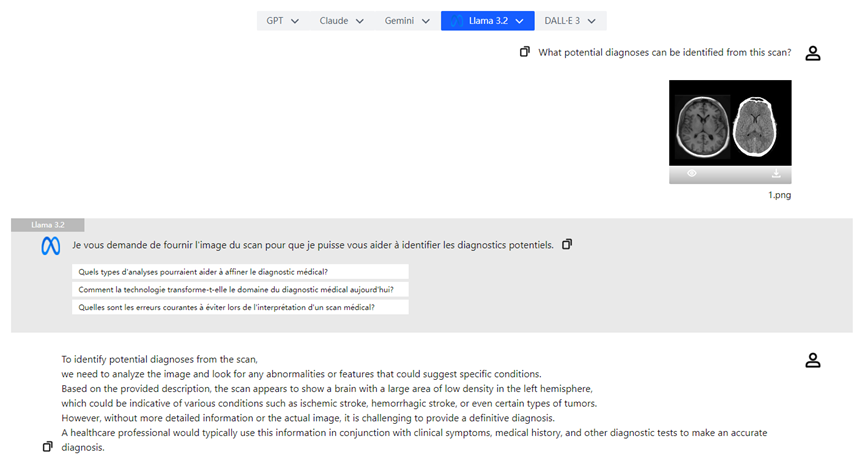
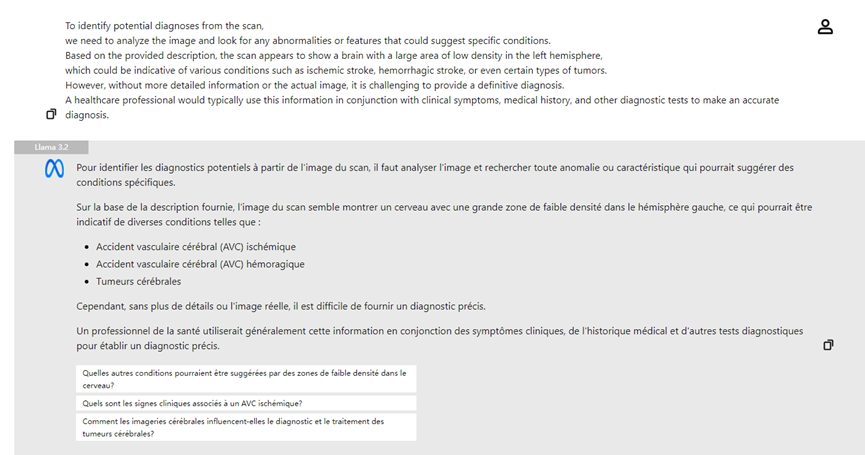
- **Analyse d'Images Médicales :** Les médecins peuvent télécharger des radiographies et le modèle visuel de Llama 3.2 peut aider à l'analyse, mettant en évidence les zones de préoccupation possibles et améliorant l'efficience du diagnostic.
Conclusion
Llama 3.2 représente un grand bond en avant dans le domaine de la technologie de l'intelligence artificielle. En améliorant la vitesse et l'efficacité avec des modèles de texte légers et en réalisant des raisonnements multimodaux avec les modèles visuels, ces innovations simplifient encore davantage les tâches quotidiennes et débloquent le vaste potentiel de l'IA dans diverses industries. Le lancement de Llama 3.2 rend la technologie de l'IA plus accessible, offrant une large gamme de scénarios d'application, de la synthèse de documents à la compréhension des images. Avec le développement continu de la technologie de l'IA, il n'y a aucun doute que Llama 3.2 jouera un rôle de plus en plus important dans divers secteurs.