Meta veröffentlicht quantisierte Versionen der Llama 3.2 1B und 3B Modelle: Reduzierter Energieverbrauch und erhöhtes Anwendungspotenzial für mobile Geräte

In der sich rasant entwickelnden Welt der künstlichen Intelligenz hat Meta am 24. Oktober 2024 offiziell quantisierte Versionen der Llama 3.2 1B und Llama 3.2 3B Modelle veröffentlicht. Diese neue Version stellt einen wichtigen Fortschritt nach der Open-Source-Veröffentlichung des Llama 3.2 Modells im September dieses Jahres dar und markiert einen weiteren großen Schritt von Meta in der Optimierung von Deep-Learning-Modellen. Mit der steigenden Nachfrage nach Anwendungen für mobile Geräte wird die Bedeutung quantisierter Modelle immer deutlicher.

Signifikante Vorteile quantisierter Modelle
Nach der Quantisierung zeigt das Llama 3.2 1B Modell in mehreren Bereichen deutliche Verbesserungen. Erstens wurde die Modellgröße im Durchschnitt um 56% reduziert, was bedeutet, dass Benutzer das Modell unter gleichen Hardwarebedingungen schneller laden und ausführen können. Zweitens wurde der RAM-Verbrauch im Durchschnitt um 41% reduziert, was besonders für ressourcenbeschränkte mobile Geräte wichtig ist. Diese Verbesserungen erhöhen nicht nur die Geschwindigkeit des Modells um das 2- bis 4-fache und maximieren so die Benutzererfahrung, sondern reduzieren auch den für den Betrieb erforderlichen Energieverbrauch, wodurch Llama 3.2 1B für verschiedene leichtgewichtige Anwendungsszenarien besser geeignet ist.
Einfach ausgedrückt ist die Modellquantisierung ein hochgradig technischer Prozess, der Fließkomma-Modelle in Festkomma-Modelle umwandelt. Dieser Prozess hilft uns, das Modell zu komprimieren und gleichzeitig die Komplexität zu reduzieren, sodass Deep-Learning-Modelle effizient auf leistungsschwächeren mobilen Geräten laufen können. Mit der zunehmenden Verbreitung intelligenter Anwendungen auf mobilen Geräten wird der Wert quantisierter Modelle immer offensichtlicher.
Erforschung technischer Quantisierungsmethoden
Um sicherzustellen, dass Llama 3.2 1B während des Quantisierungsprozesses eine hohe Leistung beibehält, verwendete Meta hauptsächlich zwei Methoden:
Quantisierungsbewusstes Training (QAT): Diese Methode legt Wert auf die Genauigkeit des Modells und stellt sicher, dass das Modell auch nach der Quantisierung eine hohe Präzision beibehält.
Post-Training-Quantisierung (SpinQuant): Konzentriert sich auf die Portabilität des Modells, sodass Llama 3.2 1B mit verschiedenen Geräten kompatibel ist, um unterschiedliche Nutzungsanforderungen zu erfüllen.
Bei dieser Veröffentlichung führte Meta auch jeweils zwei quantisierte Versionen für Llama 3.2 1B und Llama 3.2 3B ein:
Llama 3.2 1B QLoRA
Llama 3.2 1B SpinQuant
Llama 3.2 3B QLoRA
Llama 3.2 3B SpinQuant
Leistungsvergleich und praktische Anwendungen
Meta-Tests ergaben, dass das quantisierte Llama 3.2 1B Modell in Bezug auf Geschwindigkeit, RAM-Nutzung und Energieverbrauch im Vergleich zum Llama BF16 Modell signifikante Verbesserungen aufweist, während es fast die gleiche Genauigkeit wie die Llama BF16 Version beibehält. Obwohl das quantisierte Modell auf 8000 Tokens beschränkt ist (die Originalversion unterstützt 128.000), zeigen Benchmark-Ergebnisse, dass die tatsächliche Leistung der quantisierten Version immer noch nahe an Llama BF16 herankommt, was ihre Praktikabilität erheblich steigert.
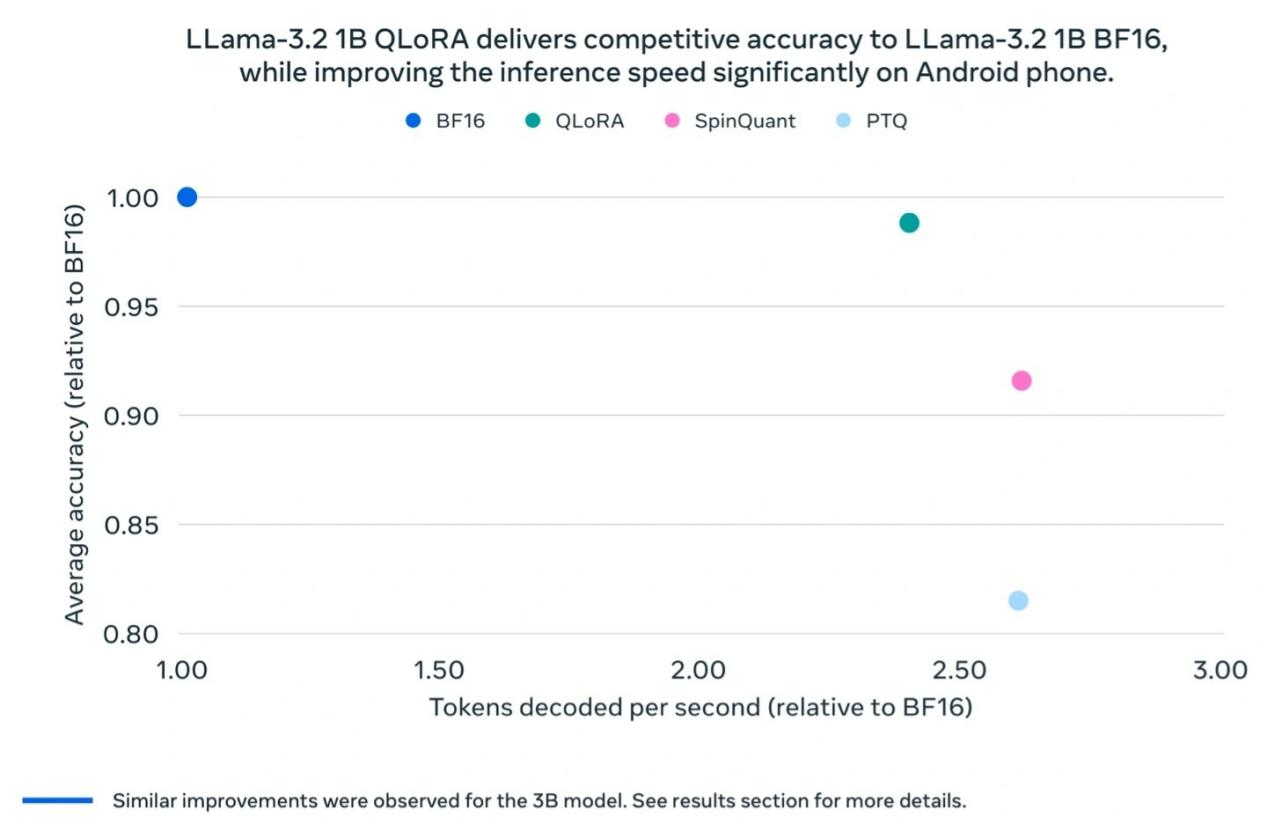
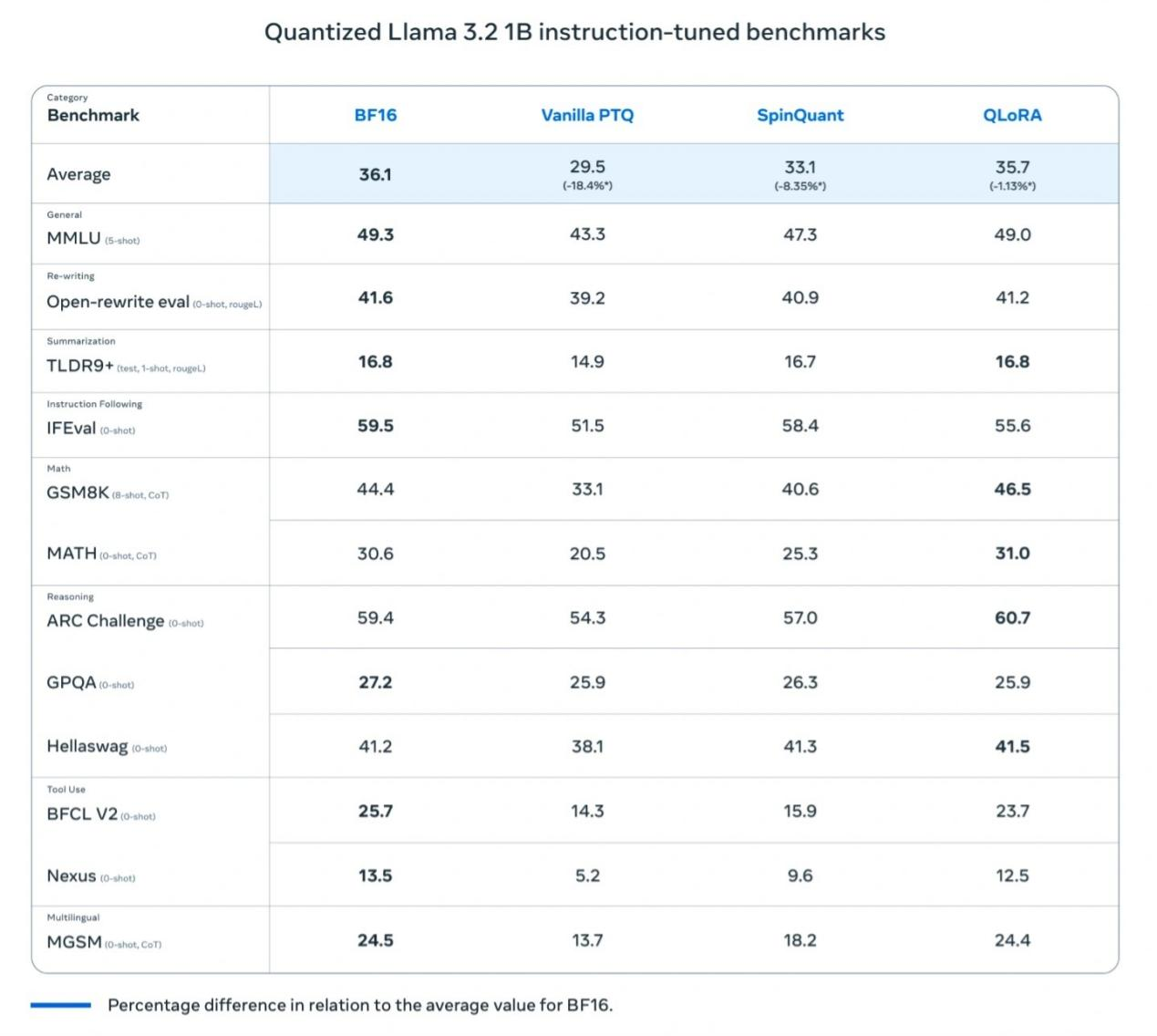
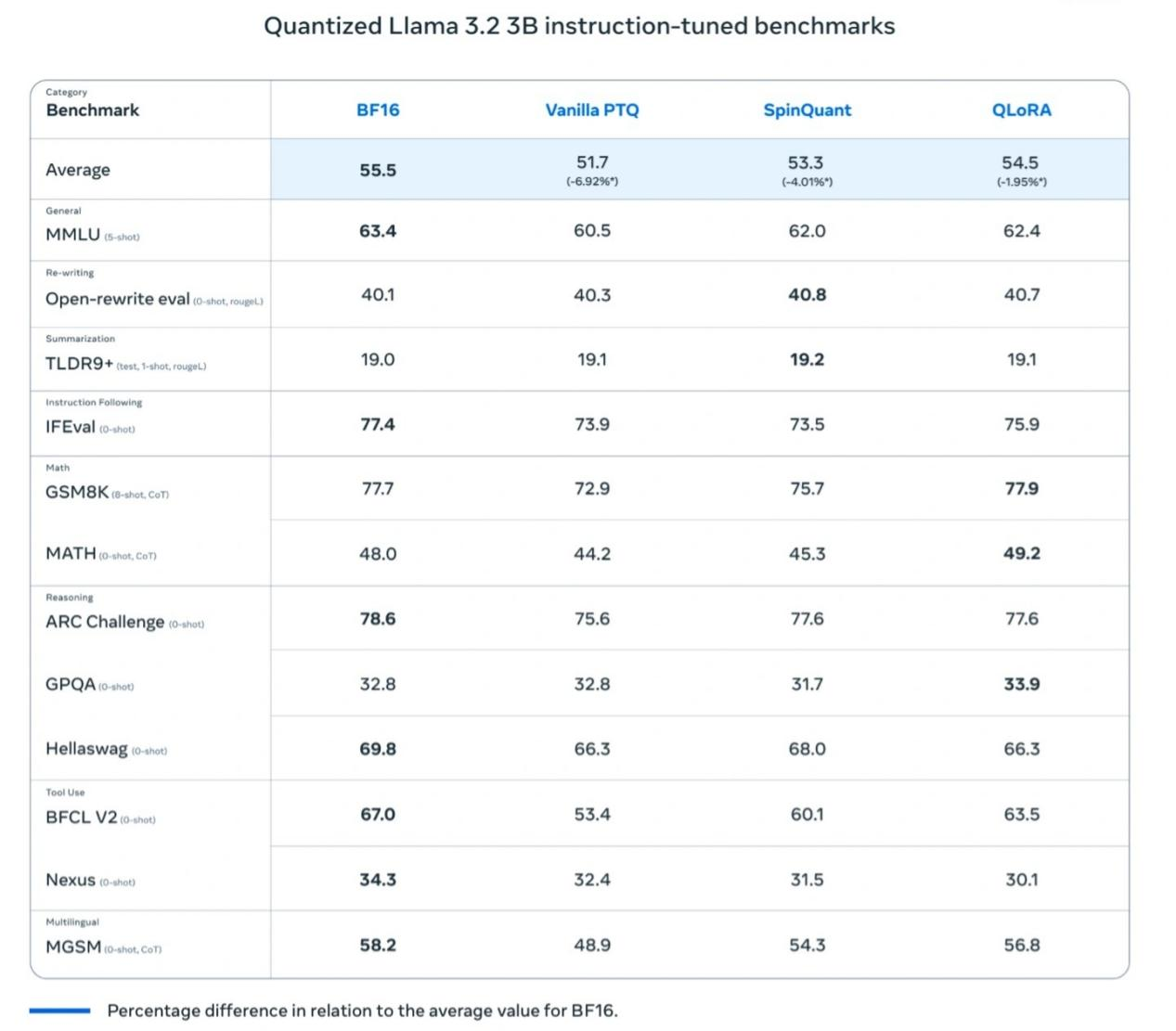
Meta führte auch Feldtests auf mehreren mobilen Plattformen durch (einschließlich OnePlus 12, Samsung S24+/S22 und nicht offengelegte Apple iOS-Geräte), die "gute Leistung" zeigten, was die Grundlage für den Erfolg des Llama 3.2 1B Modells in realen Anwendungen legt.
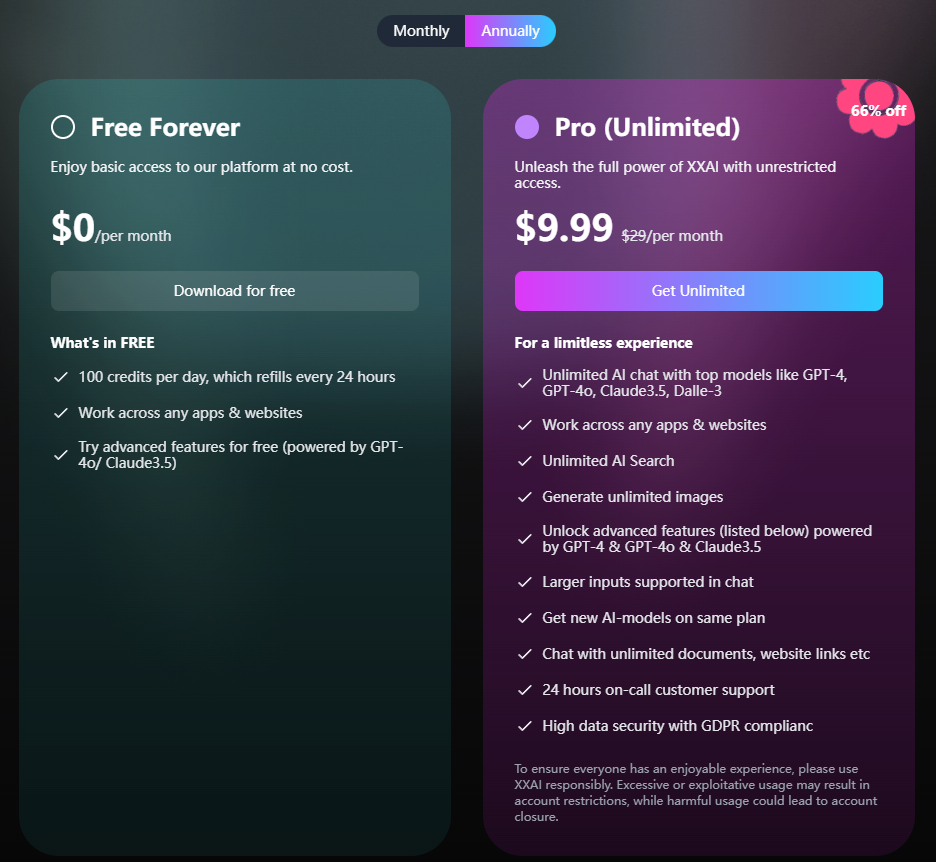
XXAI wird bald mehr KI-Modelle einführen
Die KI-Assistenzsoftware XXAI steht kurz vor einem großen Update. In diesem Update wird XXAI mehr Top-KI-Modelle einführen, darunter nicht nur die im Artikel erwähnten Llama 3.2 1B und Llama 3.2 3B, sondern auch Gemini pro 1.5, Grok2, Claude 3 Opus und andere hochrangige KI-Modelle auf dem Markt. Wichtig ist, dass XXAI in Bezug auf den Preis konstant bleibt, mit einem Jahresplan für nur 9,9 USD pro Monat, der Benutzern die Möglichkeit bietet, zu einem erschwinglichen Preis unbegrenzten Zugang zu Top-KI zu erhalten.
Fazit
Die quantisierten Versionen von Llama 3.2 1B und Llama 3.2 3B sind ein Paradebeispiel für die erfolgreiche Balance zwischen Leistungssteigerung und Energieeffizienz. Diese Innovation wird die breite Anwendung von KI-Technologie auf mobilen Geräten vorantreiben und es ermöglichen, dass immer mehr intelligente Anwendungen auf ressourcenbeschränkten Geräten reibungslos laufen. Mit Metas kontinuierlicher Erforschung und Durchbrüchen werden intelligente Geräte in Zukunft zweifellos in verschiedenen Bereichen eine noch größere Rolle spielen.