Metas Llama 3.1: Ein großer Fortschritt im Open-Source-AI

Einführung
Metas neueste Veröffentlichung, Llama 3.1, markiert einen bedeutenden Meilenstein in der künstlichen Intelligenz. Dieses Open-Source-Modell könnte die KI-Entwicklung revolutionieren, indem es erstklassige Leistungen in wichtigen Benchmarks liefert.
Die Veröffentlichung von Llama 3.1
In einem exklusiven Interview erläuterte Mark Zuckerberg, CEO von Meta, die Veröffentlichung von Llama 3.1 und dessen Bedeutung. Das Modell mit 405 Milliarden Parametern stellt das erste Mal dar, dass ein so komplexes Modell Open Source verfügbar gemacht wird.

Hauptmerkmale von Llama 3.1
- 405B Modell: Das Llama 3.1 Modell verfügt über 405 Milliarden Parameter und zählt zu den fortschrittlichsten KI-Modellen.
- Erweiterte Kontextlänge: Llama 3.1 erweitert die Kontextlänge auf 128K Tokens, weit über die 8K Tokens seines Vorgängers.
Praktische Anwendungen
Zuckerberg ist besonders begeistert von den potenziellen praktischen Anwendungen von Llama 3.1. Es wird erwartet, dass das Modell die Destillation und Feinabstimmung anderer KI-Modelle erleichtert, wobei die Kosten um bis zu 50% im Vergleich zur Nutzung von GPT-4 sinken könnten.
Kosten-Effizienz
Die wirtschaftlichen Auswirkungen von Llama 3.1 sind erheblich. Meta zielt darauf ab, KI durch eine kostengünstigere Alternative zu geschlossenen KI-Systemen zu demokratisieren und so KI für Start-ups, Unternehmen und Regierungen zugänglicher zu machen, zu einem Preis, der so erschwinglich ist wie bei XXAI.
Zugriff auf Llama 3.1
Interessierte Nutzer können Llama 3.1 über die offizielle Meta-Website ausprobieren. Das Modell ist kostenlos verfügbar, sodass Entwickler seine Funktionen erkunden können.
API-Zugang
Für die Integration in Projekte hat Meta Partnerschaften mit 25 Cloud-Anbietern, darunter AWS, NVIDIA und Google Cloud, geschlossen. Diese Zusammenarbeit stellt sicher, dass Llama 3.1 für Unternehmensnutzung leicht zugänglich ist.
Llama 3.1 in der KI-Community
Die Veröffentlichung von Llama 3.1 geht über technische Fortschritte hinaus; sie steht für die Demokratisierung der KI. Zuckerberg sieht Llama 3.1 als den „Open-Source-KI-Standard“, vergleichbar mit der Rolle von Linux bei Betriebssystemen.
Demokratisierung der KI
Meta ermöglicht es jedem Start-up, Unternehmen und jeder Regierung, eigene KI-Lösungen zu entwickeln, indem eine anpassbare und kostengünstige Alternative angeboten wird. Diese Initiative soll Chancen in der KI-Branche ausgleichen.
Exklusives Interview mit Mark Zuckerberg
Cheung: „Könnten Sie uns bitte eine Zusammenfassung der heutigen Veröffentlichung und ihrer Bedeutung geben?“
Zuckerberg: „Das große Release heute ist Llama 3.1, und wir veröffentlichen drei Modelle. Dies ist das erste Mal, dass wir ein Modell mit 405 Milliarden Parametern herausbringen. Es ist bei weitem das ausgefeilteste Open-Source-Modell, das ich je gesehen habe, und es kann in einigen Bereichen mit führenden geschlossenen Modellen konkurrieren und sie in einigen Bereichen sogar übertreffen.“
Cheung: „Die Benchmarks sehen unglaublich aus. Gibt es spezielle reale Anwendungsfälle, auf die Sie besonders gespannt sind, wie die Menschen mit diesen Modellen arbeiten werden?“
Zuckerberg: „Das, worauf ich am meisten gespannt bin, ist zu sehen, wie Menschen es nutzen, um ihre eigenen Modelle zu destillieren und zu verfeinern … Nach unseren Schätzungen wird es 50% günstiger sein, direkt auf dem 405B-Modell zu arbeiten als mit GPT-4.“
Nächste Schritte für Llama 3.1
Die Erkundung von Llama 3.1 in der KI-Community birgt enormes Potenzial für bahnbrechende Anwendungen. Von der Verbesserung der natürlichen Sprachverarbeitung bis hin zur Weiterentwicklung des maschinellen Lernens könnte Llama 3.1 ein echter Game-Changer werden.
Für weitere Informationen und um Llama 3.1 auszuprobieren, besuchen Sie den offiziellen Meta AI Blog.
Zusätzliche Gedanken von @kwindla (Daily.co)
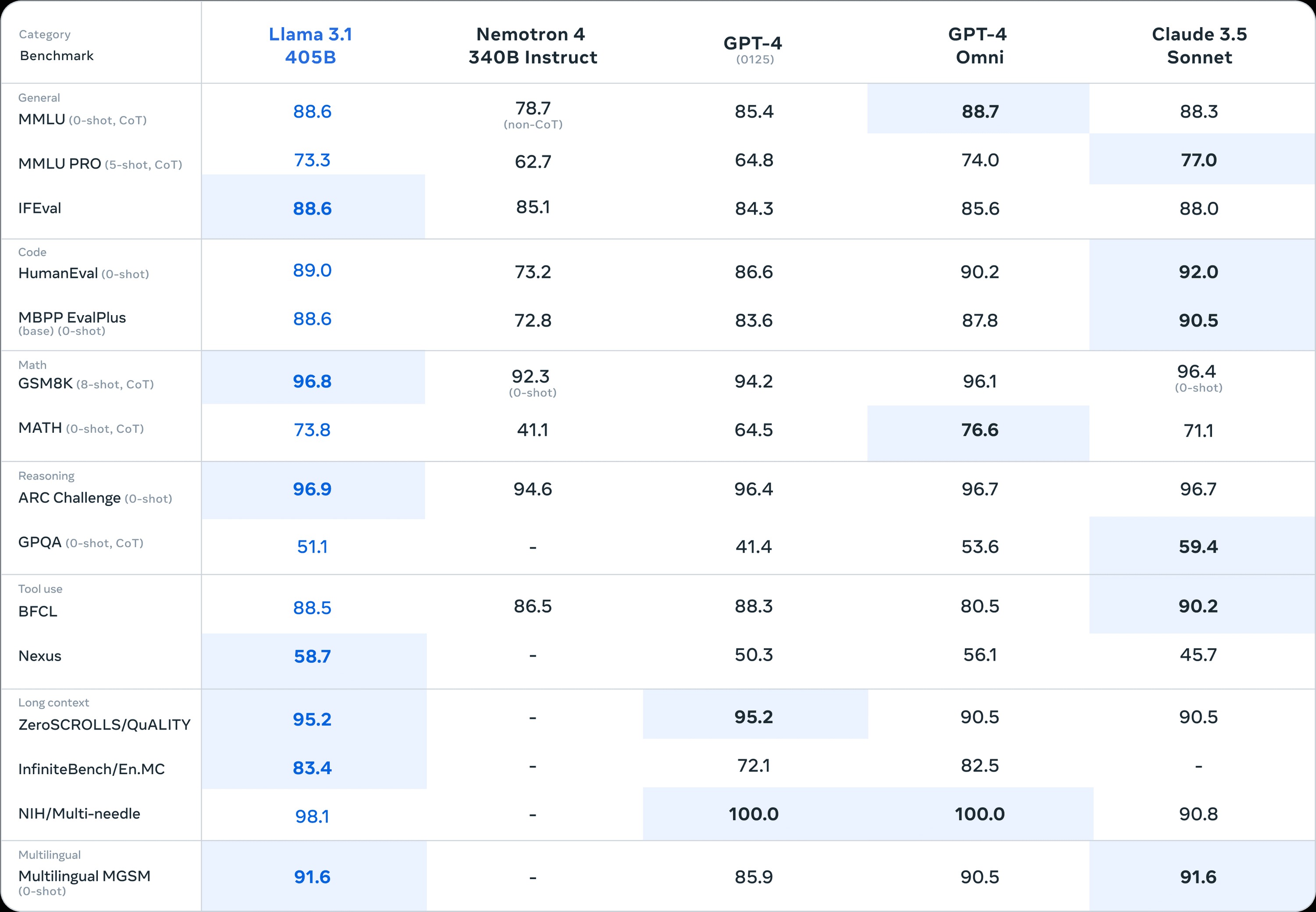
„405B schlägt GPT-4 bei 11 von 13 weit verbreiteten Benchmarks. Und Meta/Fair hat eine Geschichte der sorgfältigen Behandlung dieser Benchmarks, sodass sie fast sicherlich große Anstrengungen unternommen haben, um zu verhindern, dass Trainingsdaten in den Test gelangen usw. Kein Open-Source-Modell hat sich bisher dem GPT-4/Claude-3.5 angenähert. Es wäre ein riesiger, riesiger Deal, wenn dies genau ist und die Qualität des 'Reasoning' des Modells widerspiegelt.“
„Die beiden kleineren 3.1-Modelle (70B und 8B) haben ebenfalls große Fortschritte bei der Benchmark-Leistung erzielt. Das deutet darauf hin, dass Metas Strategie für Training/Distillation funktioniert. Modelle, die klein genug sind, um auf Einzelgeräten (oder auf LPUs, sehr, sehr schnell und kostengünstig) zu laufen und so gut sind, könnten einem Sprung über GPT-4-mini entsprechen. Dies bietet auch die Gelegenheit, wirklich gute Modelle zu verfeinern und Architektur-/Verschmelzungs-Experimente durchzuführen.“
„Große Modelle haben eine andere 'Stimmung/Atmosphäre' als kleine Modelle. 3-70B war in vielerlei Hinsicht ein ziemlich gutes Modell, aber als Konversationsagent fühlte es sich qualitativ nicht so gut an wie GPT-4 und Claude-3.5. Dieses Gefühl ist in Anwendungsfällen wie konsumentenorientierten Sprach-Chats sehr wichtig. Wenn 405B bei Benchmarks ungefähr so gut ist wie die proprietären Modelle und zum ersten Mal deren 'Stil' entspricht, ist das wirklich aufregend für eine ganze Reihe von nächsten Generationen von Konversations-/Interaktionsanwendungen.“
Fazit
Metas Llama 3.1 ist mehr als nur ein KI-Modell; es ist ein Katalysator für Veränderungen in der KI-Entwicklungscommunity. Seine Open-Source-Natur und fortschrittlichen Funktionen machen es zu einem leistungsstarken Werkzeug für diejenigen, die im Bereich der KI innovativ sein möchten.