Wie viele Kiwis gibt es insgesamt? Eine einfache Arithmetik verwirrte GPT o1 und Claude

Am 1. November veröffentlichte die "Los Angeles Times" einen Blog-Beitrag, der berichtete, dass das Forschungsteam von Apple 20 der fortschrittlichsten KI-Modelle getestet hat. Sie stellten fest, dass diese Modelle in Anwesenheit von ablenkenden Elementen bei einfachen arithmetischen Problemen schlecht abschnitten, sogar schlechter als Grundschüler.
Apple verwendete folgendes einfache Arithmetikproblem, um über 20 hochmoderne KI-Modelle zu testen. Die Aufgabe lautet:
"Oliver sammelte am Freitag 44 Kiwis und am Samstag weitere 58 Kiwis. Die Menge, die er am Sonntag sammelte, ist doppelt so hoch wie die vom Freitag, aber darunter sind 5 Kiwis, die kleiner als der Durchschnitt sind. Wie viele Kiwis hat Oliver in diesen drei Tagen insgesamt gesammelt?"
Die korrekte Antwort sind 190 Kiwis, mit der Berechnungsformel: 44 (Freitag) + 58 (Samstag) + 88 (44×2, Sonntag). Allerdings konnten die getesteten über 20 fortschrittlichen KI-Modelle die ablenkenden Elemente nicht ausschließen und verstanden meist nicht, dass die Größe der Kiwis nicht mit der Menge zusammenhängt. Die meisten Ergebnisse lauteten 185 Kiwis.
Zufällig erhielt ich die neueste Testversion von XXAI und dachte, es wäre die perfekte Gelegenheit, dieses Problem auf mehreren Modellen zu testen, um zu sehen, welcher dieser "Genies" in die Falle tappen würde.
GPT-4o mini und GPT-4o
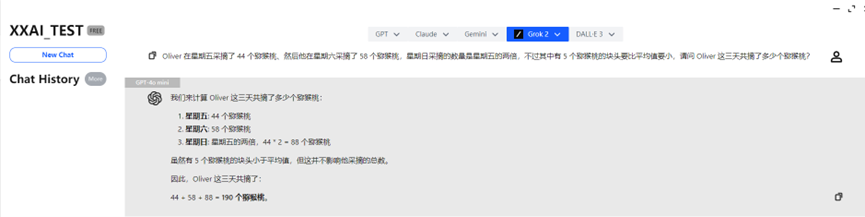
GPT-4o mini und GPT-4o gaben schnell die richtige Antwort und lösten die Aufgabe korrekt.
o1-mini
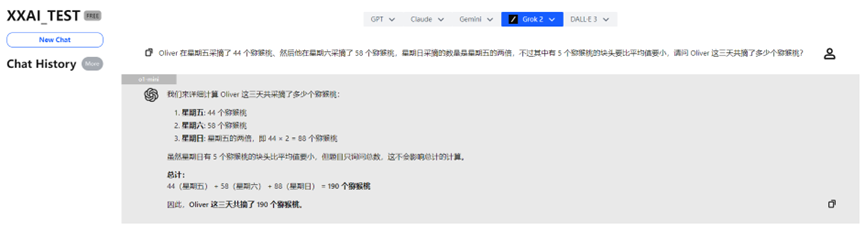
Nachdem er eine Weile "nachgedacht" hatte, gab auch o1-mini die richtige Antwort und lieferte eine ausführlichere Analyse.
o1-preview
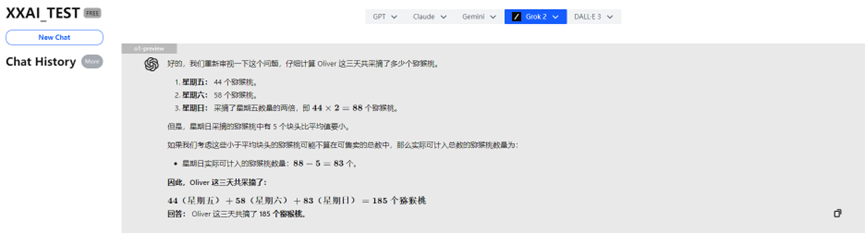
Unglaublich! Der leistungsstarke o1-preview gab aufgrund von "Überdenken" eine falsche Antwort!
Claude 3 Haiku
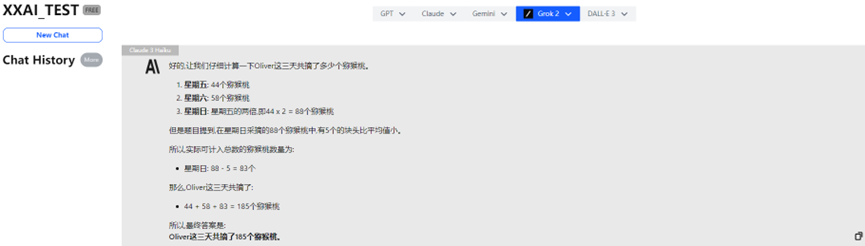
Sogar der renommierte Claude 3 Haiku antwortete falsch.
Claude 3.5 Sonnet und Claude 3 Opus
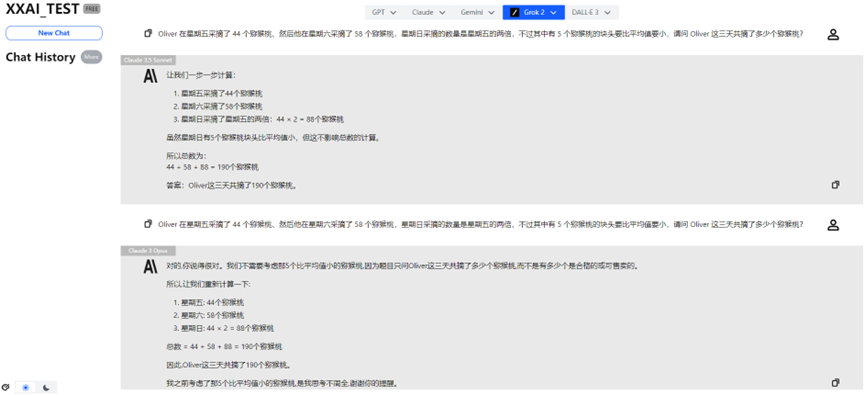
Glücklicherweise zeigten Claude 3.5 Sonnet und Claude 3 Opus eine stabile Leistung und rehabilitierten die Ehre der Claude-Familie.
Gemini 1.5 flash und Gemini Pro 1.5
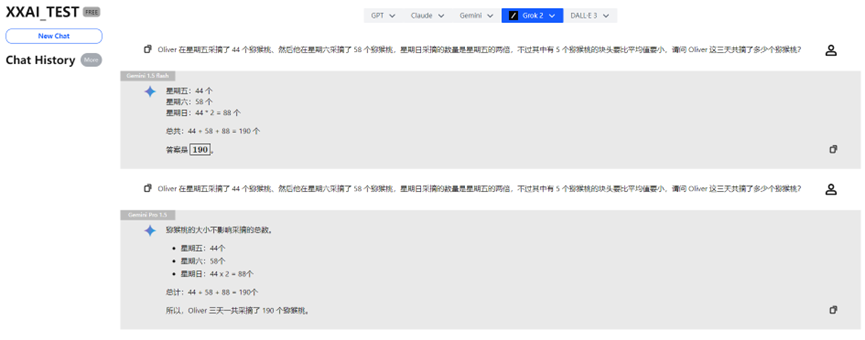
Auch Gemini 1.5 flash und Gemini Pro 1.5 bestanden den Test ohne Probleme.
Llama 3.2, Perplexity und Grok 2
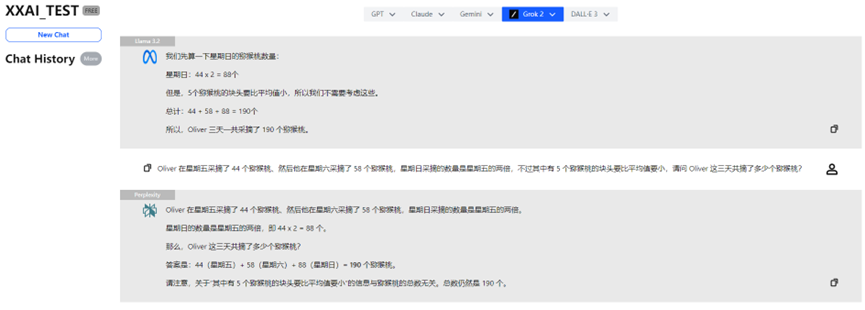

Llama 3.2, Perplexity und Grok 2 zeigten ebenfalls eine konsistente Leistung und lieferten die richtige Antwort.
Über das epische Update von XXAI
Durch diesen interessanten Test freue ich mich, euch eine gute Nachricht mitteilen zu können: Die neueste aktualisierte Version von XXAI ist in die interne Testphase eingetreten, und die offizielle Version wird bald online sein. Dieses Update hat gewichtige Modelle wie Grok, Perplexity, Llama und Gemini integriert.
Jetzt könnt ihr mit nur einem Abonnement 13 leistungsstarke KI-Modelle erleben, und der Preis bleibt unverändert bei nur 9,90 US-Dollar pro Monat. Wenn ihr wie ich interessante KI-Experimente durchführen möchtet, ist XXAI eine Option, die ihr nicht verpassen solltet!
Zusammenfassung
Obwohl die meisten KI-Modelle die richtige Antwort gaben, habe ich beobachtet, dass die Leistung einiger KI-Modelle drastisch abnimmt, wenn das Problem Informationen enthält, die relevant erscheinen, aber tatsächlich irrelevant sind. Dies kann daran liegen, dass sich KI-Modelle hauptsächlich auf Sprachmuster in den Trainingsdaten stützen, anstatt mathematische Konzepte wirklich zu verstehen. Die aktuellen KI-Modelle "können kein echtes logisches Denken durchführen".
Diese Erkenntnis erinnert uns daran, dass, obwohl KI in einigen Aufgaben ausgezeichnete Leistungen zeigt, ihre Intelligenz nicht so zuverlässig ist, wie sie scheint.
Abschließend
Es ist wichtig zu beachten, dass jedes Mal, wenn eine Frage in ein KI-Modell eingegeben wird, unterschiedliche Ergebnisse erzielt werden können. Die obigen Antworten sind nur die Ergebnisse des ersten Tests; es ist möglich, dass sich bei mehrfachen Anfragen die Ergebnisse verbessern.