Llama 3.2:AIの実用化を簡素化

最近、XXAIは最新バージョンを更新し、Llama 3.2などのAIモデルをアプリケーションに統合しました。多くの人々は疑問に思うかもしれませんが、強力なAIモデルが統合されても、それを実際のアプリケーションでどのように使用するか、それぞれの利点はどこにあるのでしょうか?これらの疑問に対する答えを探るため、私はこれらのAIモデルについての資料を調査し、評価を行いました。このブログ記事では、Llama 3.2の詳細な紹介といくつかの使用感をシェアします。
Metaが最新リリースしたLlama 3.2は、単なる言語モデルのアップデートにとどまらず、人工知能技術がマルチモーダルシステムに向かう重要な一歩となっています。Llama 3.2はテキストと視覚能力を統合し、4つの新しいモデルを導入しました:2つの軽量テキストモデル(1Bと3B)と2つの視覚モデル(11Bと90B)です。これらのモデルの登場は、Llama 3.2がAIアプリケーション分野での幅広い適応性を示しており、長文ドキュメントの要約から複雑な画像理解に至るまで、様々な実際のタスクに解決策を提供します。
マルチモーダルシステムへの移行
AI技術の急速な発展に伴い、マルチモーダルシステムは主流になりつつあります。Llama 3.2はテキストの処理だけでなく、画像の理解や推論も可能であり、AIのクロスドメイン能力を実現しています。過去のAIモデルはテキストまたは画像を別々に処理することしかできませんでしたが、Llama 3.2は言語と視覚の処理能力を統合することで、AIにより強力なマルチタスク能力を与えています。例えば、Llama 3.2は長編の記事を読むと同時に画像内容を分析することができ、地図を理解しつつ会話ができるアシスタントのような存在です。
Llama 3.2の軽量テキストモデル
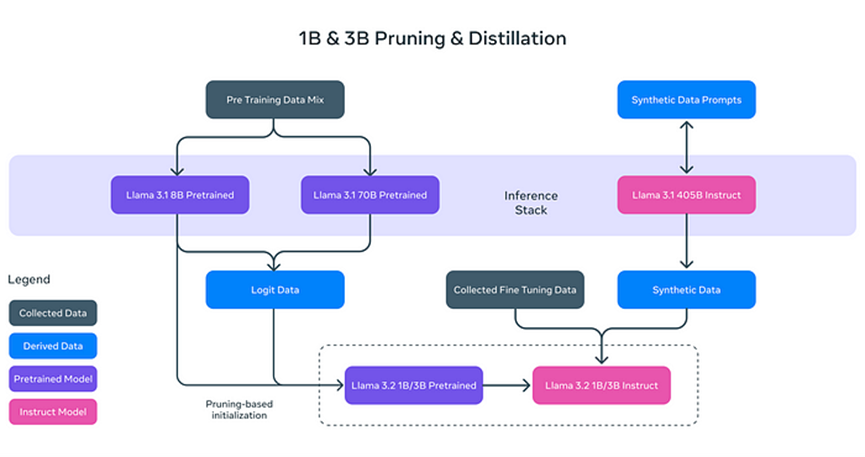
Llama 3.2の2つの軽量テキストモデル(1Bと3B)は効率的に設計されており、ローカルデバイス上で大量の文脈情報を処理することができます。例えば、3Bモデルは最大128,000トークンのデータを同時に処理できます。これは、Llama 3.2の軽量モデルがドキュメント要約や内容のリライトなどのタスクを効率的に実行できることを意味しており、大きな計算資源への依存を減少させます。
Llama 3.2のテキストモデルが「軽量」である理由は、単にモデル規模を減らしたのではなく、革新的な技術を用いてモデルの効率を向上させているからです。具体的には、次の2つの技術によって軽量化を実現しています:
- **プルーニング(Pruning)**:モデル内の重要でない部分を削除し、その性能と効率性を維持します。
- **蒸留(Distillation)**:大規模モデル(例えばLlama 3.1の8B)から知識を抽出して小さなモデルに圧縮し、重要な情報を保ちます。
これらの軽量化モデルは処理速度の向上だけでなく、スマートフォンや個人用コンピュータなどのデバイスでLlama 3.2を稼働可能にし、AIアプリケーションのハードウェア要件を大幅に低減させます。
ポストトレーニング:微細調整と整合
プルーニングと蒸留を経たLlama 3.2のテキストモデルは、更にポストトレーニング最適化を通じて実際のタスクでの性能を向上させています。これには次のものが含まれます:
- **スーパーバイズドファインチューニング(SFT)**:モデルが様々なタスクでより正確に動作するよう細かく指導されます。
- **拒否サンプリング(RS)**:生成された候補の中から最適な質の応答を選び出します。
- **ダイレクトプリファレンスオプティマイゼーション(DPO)**:ユーザーの好みに基づき生成された応答をランク付けします。
これらのポストトレーニングステップにより、Llama 3.2は複雑なテキストタスクを処理し、異なる問題に最適な回答を提供することが可能となっています。
Llama 3.2の視覚能力
Llama 3.2のもう一つの注目点は、その強力な視覚モデルです。11Bと90Bモデルの導入により、Llama 3.2はテキスト理解に加え、画像とその内容を解析することが可能となっています。例えば、Llama 3.2は画像内の複雑な視覚情報を認識し、記述に基づいて「視覚的配置」を行うことができます。この能力により、Llama 3.2は医療や教育などの分野で強力なサポートを提供します。
Llama 3.2の視覚モデルは**アダプターウェイト(Adapter Weights)**技術を採用しており、画像エンコーダーと言語モデルの間でシームレスな接続を可能にしています。これによりLlama 3.2はテキストと画像を同時に理解し、両者を組み合わせて推論を行うことができます。例えば、ユーザーがレストランのメニュー写真をアップロードすると、Llama 3.2はユーザーの好み(例えば「ベジタリアン」)に基づいて関連する料理を強調表示します。
他のマルチモーダルモデルとの比較
Llama 3.2のオープンソースとカスタマイズ能力は、同市場で独自の地位を占めています。OpenAIのGPTと比較すると、GPTのマルチモーダルバージョンもテキストと画像処理をサポートしていますが、通常はクローズドソースであり、簡単にカスタマイズや微調整ができません。一方、MistralのPixTralは比較的軽量ですが、Llama 3.2は柔軟性とカスタマイズ性の面で依然として利点を有しています。
Llama 3.2はテキストと画像タスクの処理をサポートするだけでなく、ユーザーの要求に基づいて微調整を行い、個別のアプリケーションニーズに応えることができます。
実際の応用シーン
Llama 3.2のマルチモーダル能力は多くの分野でその強力な潜在力を示しています:
- **ドキュメント要約**:軽量テキストモデルにより、Llama 3.2は大量のドキュメントやPDFを迅速に要約し、重要な情報を抽出します。
- **画像説明**:Llama 3.2は正確な画像キャプションを自動生成し、ユーザーが視覚コンテンツをよりよく理解するのを支援します。
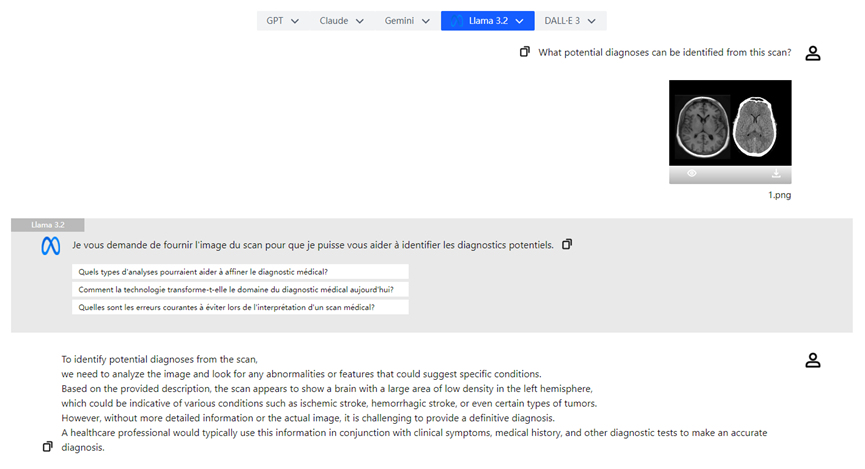
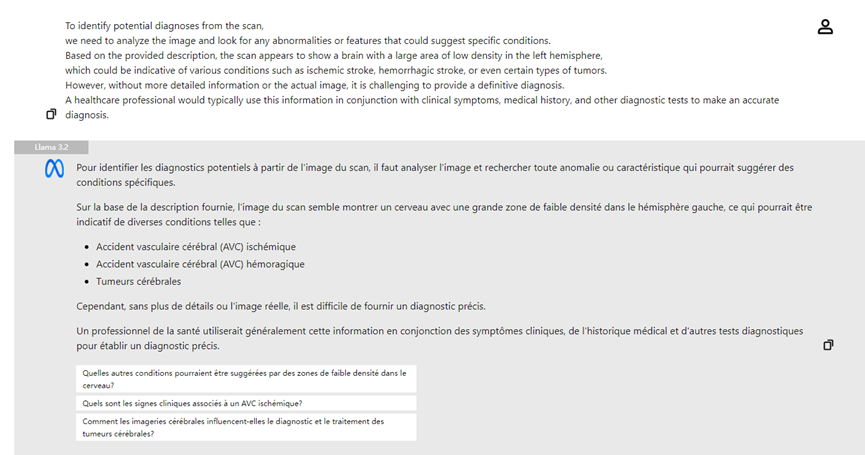
- **医療画像分析**:医者はX線写真をアップロードし、Llama 3.2の視覚モデルは分析を支援し、病変の可能性がある領域を強調して診断効率を向上させます。
結論
Llama 3.2は人工知能技術の大きな進歩を具現化しています。軽量テキストモデルにより処理速度と効率を向上させ、視覚モデルによって図文結合のマルチモーダル推論を実現しました。これらの革新は日常のタスクをさらに簡素化し、各産業におけるAIの巨大な潜在力を解き放つ手助けをしています。Llama 3.2の導入により、AI技術はより普及し、ドキュメント要約から画像理解までの広範な応用シーンを提供しました。AI技術の継続的な発展とともに、Llama 3.2は間違いなく各産業でますます重要な役割を果たすことでしょう。