Llama 3.2: Simplificando la Aplicación de la IA en el Mundo Real

Recientemente, XXAI actualizó su plataforma integrando modelos avanzados de IA como Llama 3.2. Muchas personas pueden preguntarse cómo utilizar de manera efectiva estos poderosos modelos de IA en aplicaciones prácticas y cuáles son las ventajas específicas de cada modelo. Para abordar estas inquietudes, investigué y evalué la información más reciente sobre estos modelos de IA. En este artículo, proporcionaré una introducción detallada a Llama 3.2 y compartiré algunas impresiones basadas en mi experiencia.
El último lanzamiento de Meta, Llama 3.2, no es solo una actualización de un modelo de lenguaje; es un paso significativo hacia los sistemas de IA multimodales. Llama 3.2 combina capacidades textuales y visuales, introduciendo cuatro nuevos modelos: dos modelos de texto ligeros (1B y 3B) y dos modelos visuales (11B y 90B). Estos modelos marcan la amplia adaptabilidad de Llama 3.2 en aplicaciones de IA, ofreciendo soluciones para tareas que van desde la síntesis de documentos extensos hasta la comprensión compleja de imágenes.
Transición hacia un Sistema Multimodal
Con el rápido desarrollo de la tecnología de IA, los sistemas multimodales se están convirtiendo en algo convencional. Llama 3.2 es capaz de procesar tanto texto como imágenes, realizando verdaderamente las capacidades inter-disciplinares de la IA. Anteriormente, los modelos de IA solo podían manejar texto o imágenes por separado. Sin embargo, Llama 3.2 refuerza las habilidades multitarea de la IA integrando el procesamiento del lenguaje y las imágenes. Por ejemplo, Llama 3.2 puede leer artículos extensos mientras analiza el contenido de las imágenes, actuando como un asistente que puede comprender mapas y conversar contigo.
Modelos de Texto Ligeros de Llama 3.2
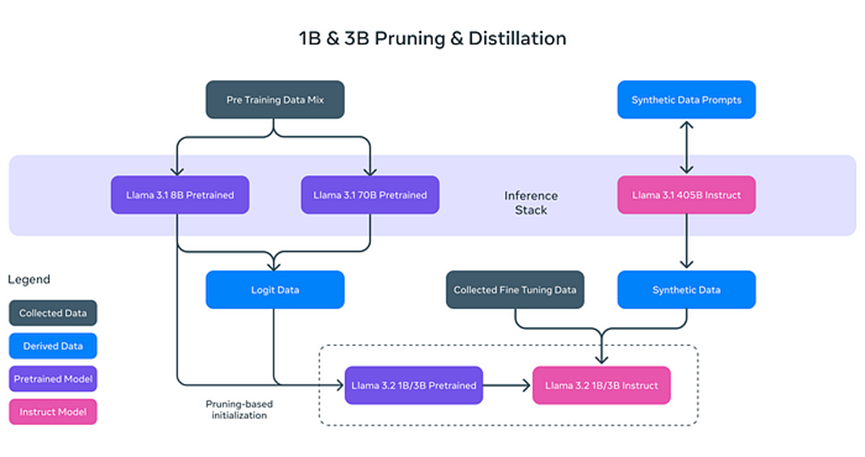
Los dos modelos de texto ligeros de Llama 3.2 (1B y 3B) están diseñados para ser eficientes y pueden manejar una gran cantidad de información contextual en dispositivos locales. Por ejemplo, el modelo 3B puede procesar hasta 128,000 tokens de datos simultáneamente. Esto significa que los modelos ligeros pueden realizar tareas como resumir documentos y reescribir contenido sin depender excesivamente de recursos computacionales poderosos.
¿Por qué los modelos de texto de Llama 3.2 son "ligeros"? No se trata simplemente de reducir el tamaño del modelo, sino de aumentar su eficiencia mediante técnicas innovadoras:
- **Poda (Pruning):** Elimina las partes no esenciales del modelo mientras mantiene su rendimiento y eficiencia, similar a podar ramas de un árbol para un crecimiento más saludable y eficiente.
- **Destilación (Distillation):** Extrae y comprime el conocimiento de modelos grandes (como el 8B de Llama 3.1) en modelos más pequeños, asegurando que la información esencial no se pierda.
Estos modelos ligeros no solo mejoran la velocidad de procesamiento, sino que también permiten que Llama 3.2 funcione en dispositivos como teléfonos inteligentes y computadoras personales, reduciendo significativamente los requisitos de hardware para las aplicaciones de IA.
Post-Entrenamiento: Afinación y Alineación
Tras la poda y la destilación, los modelos de texto de Llama 3.2 pasan por una optimización de post-entrenamiento para mejorar su rendimiento en tareas reales. Esto incluye:
- **Afinación Supervisada (SFT):** El modelo aprende detenidamente cómo desempeñarse con mayor precisión en diversas tareas, como la síntesis de documentos y la traducción de textos.
- **Muestreo de Rechazo (RS):** Genera múltiples respuestas posibles y selecciona la de mejor calidad.
- **Optimización de Preferencias Directas (DPO):** Clasifica las respuestas generadas según las preferencias del usuario, ofreciendo respuestas más acordes a sus necesidades.
Estos pasos de post-entrenamiento permiten que Llama 3.2 maneje tareas complejas de texto y proporcione las respuestas más adecuadas para diferentes problemas.
Capacidades Visuales de Llama 3.2
Otro aspecto destacado de Llama 3.2 son sus potentes modelos visuales. Con la introducción de los modelos 11B y 90B, Llama 3.2 puede analizar e interpretar contenido de imágenes, además de comprender texto. Por ejemplo, Llama 3.2 puede reconocer información visual compleja en imágenes y realizar "localización visual" basada en descripciones. Esta capacidad es especialmente útil en campos como la medicina y la educación.
El modelo visual de Llama 3.2 utiliza la tecnología de **Pesos de Adaptadores (Adapter Weights)**, que permite una integración fluida entre los codificadores de imágenes y los modelos de lenguaje. Esto permite a Llama 3.2 comprender simultáneamente texto e imágenes, y usar ambas fuentes para razonar. Por ejemplo, un usuario puede subir una foto de un menú de restaurante y Llama 3.2 puede resaltar los platos relevantes según las preferencias del usuario (como "vegetariano").
Comparación con Otros Modelos Multimodales
El código abierto y la capacidad de personalización de Llama 3.2 le otorgan una posición única en el mercado. En comparación con GPT de OpenAI, que también admite el procesamiento de texto e imágenes, Llama 3.2 ofrece mayor flexibilidad, ya que las versiones multimodales de GPT suelen ser de código cerrado y no son fácilmente personalizables. Mientras que PixTral de Mistral es relativamente ligero, Llama 3.2 aún se presenta como superior en cuanto a flexibilidad y capacidad de personalización.
Llama 3.2 no solo maneja tareas de texto e imagen, sino que también se puede ajustar finamente de acuerdo con las necesidades del usuario, cumpliendo con las demandas de aplicaciones personalizadas.
Escenarios de Aplicación Real
La capacidad multimodal de Llama 3.2 demuestra un potencial significativo en diversos campos:
- **Síntesis de Documentos:** Gracias a sus modelos de texto ligeros, Llama 3.2 puede resumir rápidamente grandes cantidades de documentos o archivos PDF, extrayendo información clave.
- **Descripción de Imágenes:** Llama 3.2 puede generar automáticamente subtítulos de imágenes precisos, ayudando a los usuarios a comprender mejor el contenido visual.
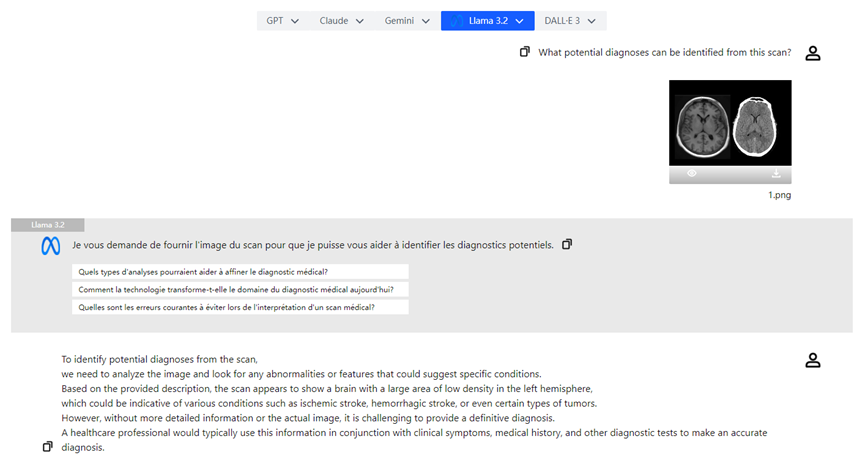
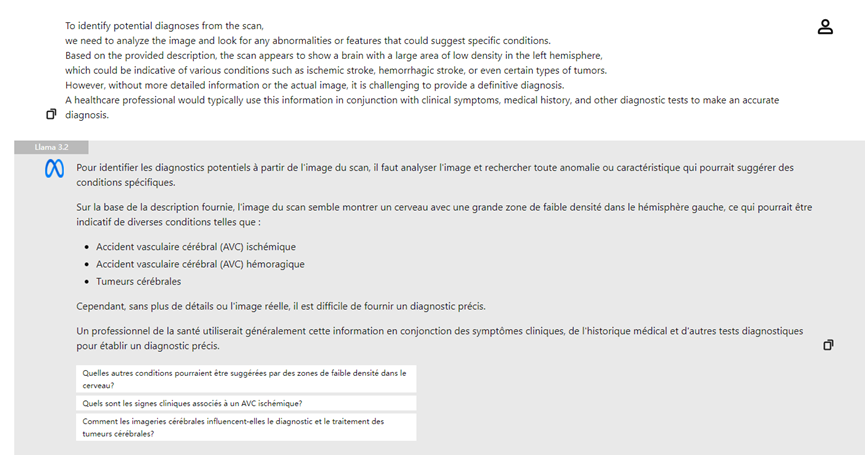
- **Análisis de Imágenes Médicas:** Los médicos pueden subir radiografías y el modelo visual de Llama 3.2 puede ayudar en el análisis, destacando posibles áreas de preocupación y mejorando la eficiencia diagnóstica.
Conclusión
Llama 3.2 representa un gran avance en la tecnología de inteligencia artificial. Al mejorar la velocidad y eficiencia de procesamiento con modelos de texto ligeros y lograr razonamientos multimodales con modelos visuales, estas innovaciones simplifican aún más las tareas diarias y desbloquean el vasto potencial de la IA en varias industrias. El lanzamiento de Llama 3.2 hace que la tecnología de IA sea más accesible, ofreciendo una amplia gama de escenarios de aplicación, desde la síntesis de documentos hasta la comprensión de imágenes. Con el continuo desarrollo de la tecnología de IA, no hay duda de que Llama 3.2 jugará un papel cada vez más importante en diversos sectores.