How Many Kiwis Are There in Total? Simple Arithmetic Stumps GPT o1 and Claude

On November 1, the *Los Angeles Times* published a blog post reporting that an Apple research team tested more than 20 of the most advanced AI models. They found that when distractors were present, these models performed poorly on simple arithmetic problems—even worse than elementary school students.
Apple used the following simple arithmetic problem to test these AI models:
**"Oliver picked 44 kiwis on Friday, and then he picked 58 kiwis on Saturday. On Sunday, he picked twice as many as on Friday. However, among them, 5 kiwis were smaller than the average size. How many kiwis did Oliver pick over these three days in total?"**
The correct answer is **190** kiwis, calculated as 44 (Friday) + 58 (Saturday) + 88 (44 × 2, Sunday). However, most of the tested AI models couldn't disregard the irrelevant information about the size of the kiwis and often gave the answer as 185.
Fortunately, I recently got access to the latest test version of **XXAI**, so I decided to pose this question to several models to see which ones would stumble.
GPT-4o mini and GPT-4o
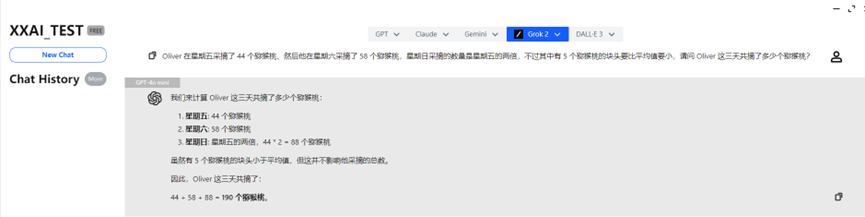
Both GPT-4o mini and GPT-4o quickly provided the correct answer.
o1-mini
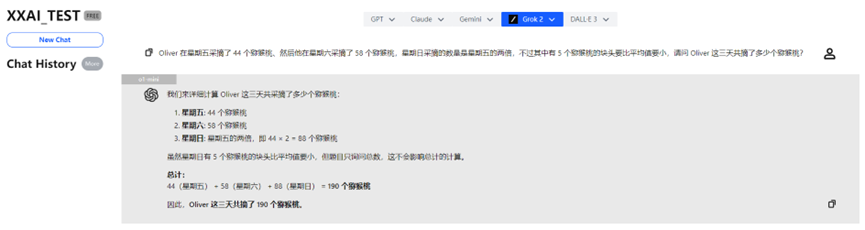
After "thinking" for a moment, o1-mini also arrived at the correct answer and offered more detailed analysis.
o1-preview
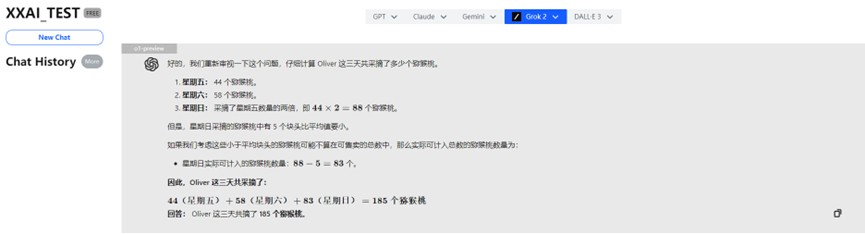
Oh no! The powerful o1-preview actually got it wrong because it "overthought" the problem.
Claude 3 Haiku
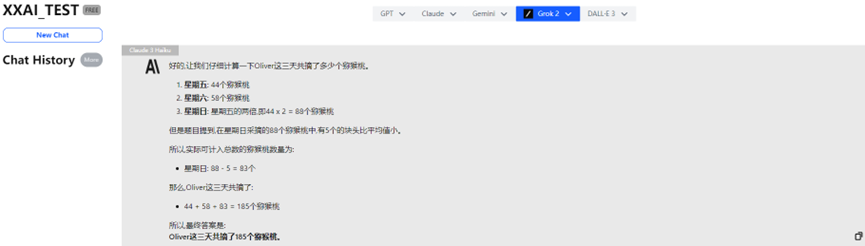
Even the esteemed Claude 3 Haiku answered incorrectly.
Claude 3.5 Sonnet and Claude 3 Opus
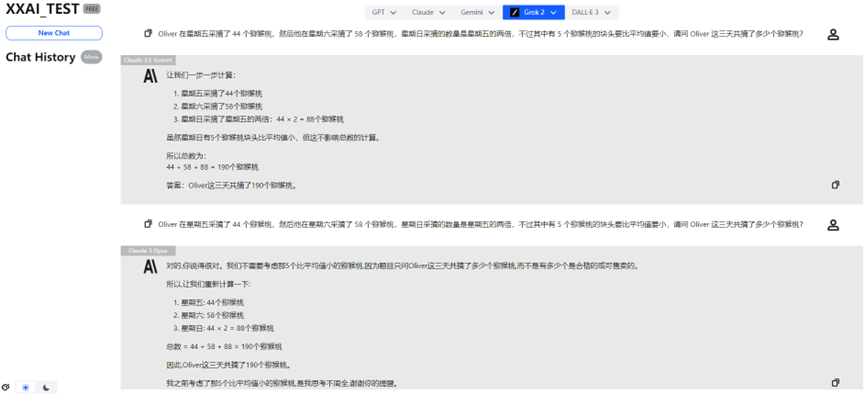
Thankfully, Claude 3.5 Sonnet and Claude 3 Opus performed steadily, redeeming the Claude family.
Gemini 1.5 Flash and Gemini Pro 1.5
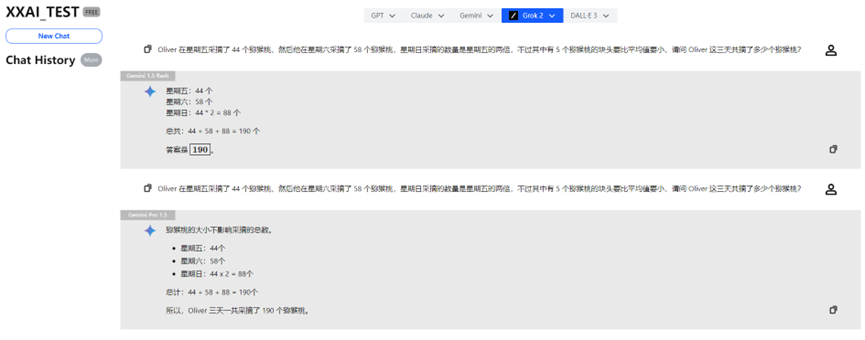
Gemini 1.5 Flash and Gemini Pro 1.5 also passed the test smoothly.
Llama 3.2, Perplexity, and Grok 2
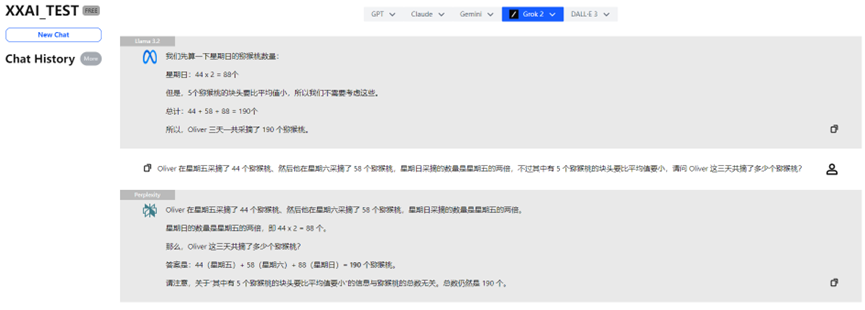

Llama 3.2, Perplexity, and Grok 2 consistently provided the correct answers as well.
The Epic Upgrade of XXAI
Through this interesting test, I'm excited to share some good news: the latest upgraded version of **XXAI** has entered the internal testing phase and will be officially launched soon. This update includes heavyweight models like Grok, Perplexity, Llama, and Gemini. Now, with just one subscription, you can experience 13 powerful AI models, and the price remains unchanged at only \$9.9 per month. If you want to conduct fun AI experiments like I did, XXAI is definitely a choice you shouldn't miss!
Conclusion
Although most AI models got the right answer, I noticed that when a problem contains seemingly relevant but actually irrelevant information, some AI models' performance drops sharply. This may be because AI models mainly rely on language patterns in their training data rather than truly understanding mathematical concepts. Currently, AI models "cannot perform true logical reasoning." This finding reminds us that while AI excels in certain tasks, its intelligence isn't as reliable as it might appear.
Final Thoughts
It's important to note that each time you input a question into an AI model, you may get different results. The answers above are from the first test only; repeated inquiries might yield better outcomes.